

OpenAI ha ridotto del 40% la latenza end-to-end negli agentic workflows introducendo il supporto WebSocket API nella Responses API, permettendo agli sviluppatori di sfruttare modelli che raggiungono oltre 1.000 token al secondo senza colli di bottiglia infrastrutturali.
Per chi integra API di intelligenza artificiale in produzione, il dato non è solo tecnico: significa che le attese tra una chiamata e l'altra — quelle che oggi frammentano l'esperienza utente in tool come Codex, Cursor o Cline — possono essere tagliate drasticamente, rendendo gli agenti AI percepibilmente più reattivi.
Come funziona il WebSocket mode nella Responses API
Fino a novembre 2025, ogni richiesta alla Responses API veniva trattata come indipendente: anche per conversazioni multi-turn, il sistema ricostruiva da zero il contesto, ripetendo tokenizzazione, validazione e routing. Un approccio funzionante quando l'inferenza sui GPU era il collo di bottiglia principale, ma diventato inefficiente con modelli specializzati come GPT-5.3-Codex-Spark, ottimizzati per superare i 1.000 token per secondo (TPS) su hardware Cerebras.
La soluzione è stata ripensare il protocollo di trasporto. Invece di aprire una nuova connessione HTTP per ogni follow-up, OpenAI ha introdotto una connessione persistente via WebSocket che mantiene in memoria lo stato della conversazione. Quando il client invia una nuova richiesta con il parametro previous_response_id, il server recupera dallo cache in-memory: l'oggetto risposta precedente, gli item di input/output, le definizioni dei tool e gli artefatti di sampling già renderizzati.
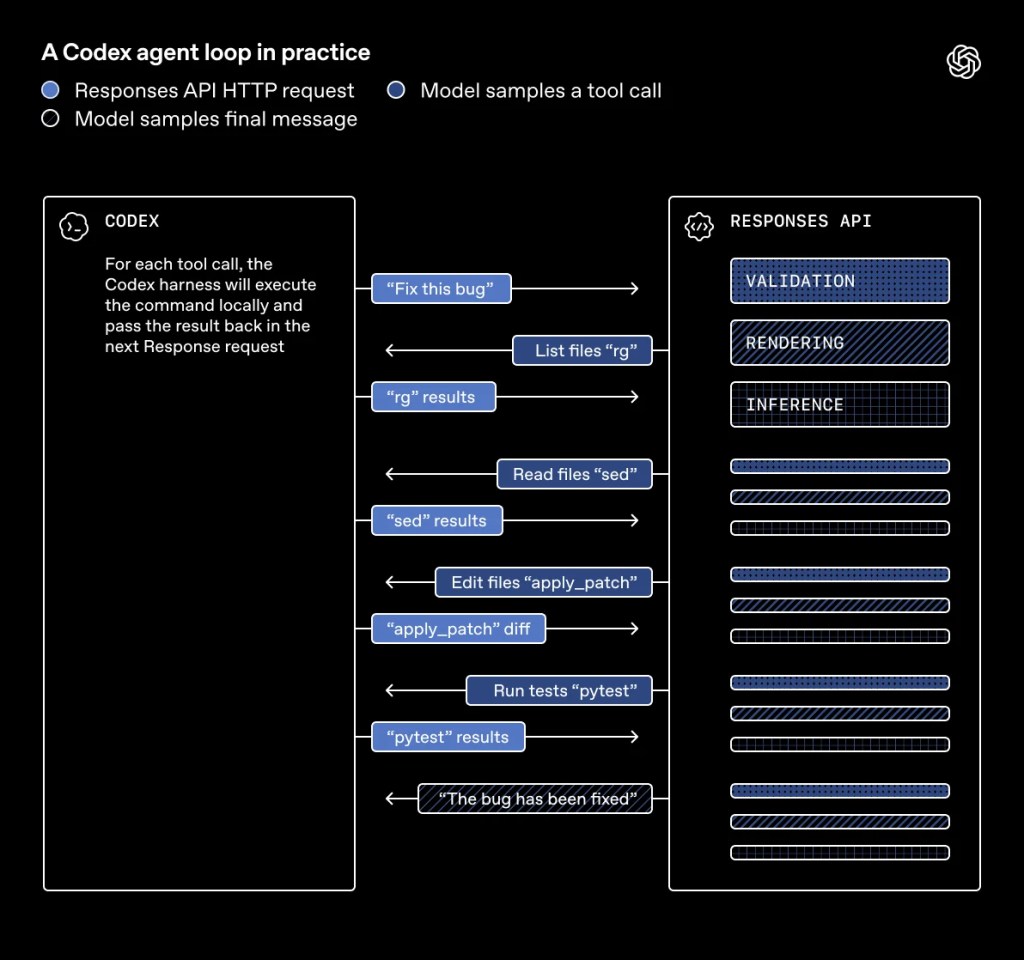
Un ciclo di agenti Codex nella pratica , OpenAI
- Risponde alla richiesta API HTTP,
- campioni del modello – messaggio finale,
- campioni di modelli, una chiamata a uno strumento.
“WebSocket mode is one of the most significant new capabilities in the Responses API since its launch in March 2025.” — Brian Yu e Ashwin Nathan, OpenAI
Questo design permette di eseguire il lavoro pre-inferenza una sola volta, mettere in pausa il loop di sampling durante l'esecuzione di tool locali, e completare il post-processing in modo incrementale. Il risultato: eliminazione del lavoro ridondante e riduzione drastica del time to first token (TTFT), migliorato del 45% già nella fase di ottimizzazione preliminare.
La domanda che nessun comunicato OpenAI si pone esplicitamente: accelerare l'infrastruttura serve a consegnare valore agli utenti finali, o a mascherare il fatto che i modelli, da soli, non bastano più a differenziarsi?
I numeri reali dopo il lancio
Dopo un alpha test con startup specializzate in coding agent, i dati di produzione confermano l'impatto. Codex ha migrato la maggior parte del traffico su WebSocket mode, registrando miglioramenti di latenza coerenti con gli obiettivi. Per GPT-5.3-Codex-Spark, OpenAI ha raggiunto il target di 1.000 TPS con picchi fino a 4.000 TPS, dimostrando che l'infrastruttura API può tenere il passo con inferenza ultra-rapida.
Gli effetti si misurano anche nell'ecosistema di integrazione:
- Vercel ha integrato il supporto WebSocket nell'AI SDK, riducendo la latenza fino al 40% per i flussi di lavoro basati su OpenAI.
- Cline riporta workflow multi-file il 39% più veloci.
- In Cursor, l'uso di modelli OpenAI è diventato fino al 30% più rapido.
Questi numeri non sono marginali: in un contesto competitivo dove la reattività percepita influenza direttamente l'adozione, un miglioramento del 30-40% può spostare la preferenza degli sviluppatori verso stack che sfruttano WebSocket API.
Cosa cambia per sviluppatori e team italiani
Chi segue il settore da vicino sa che questi annunci arrivano sempre a mercati chiusi — e che i numeri ufficiali raccontano solo metà della storia. Per i team di sviluppo italiani, l'adozione di WebSocket mode richiede modifiche minime al codice: basta mantenere la forma familiare di response.create e aggiungere il parametro previous_response_id per abilitare il caching dello stato.
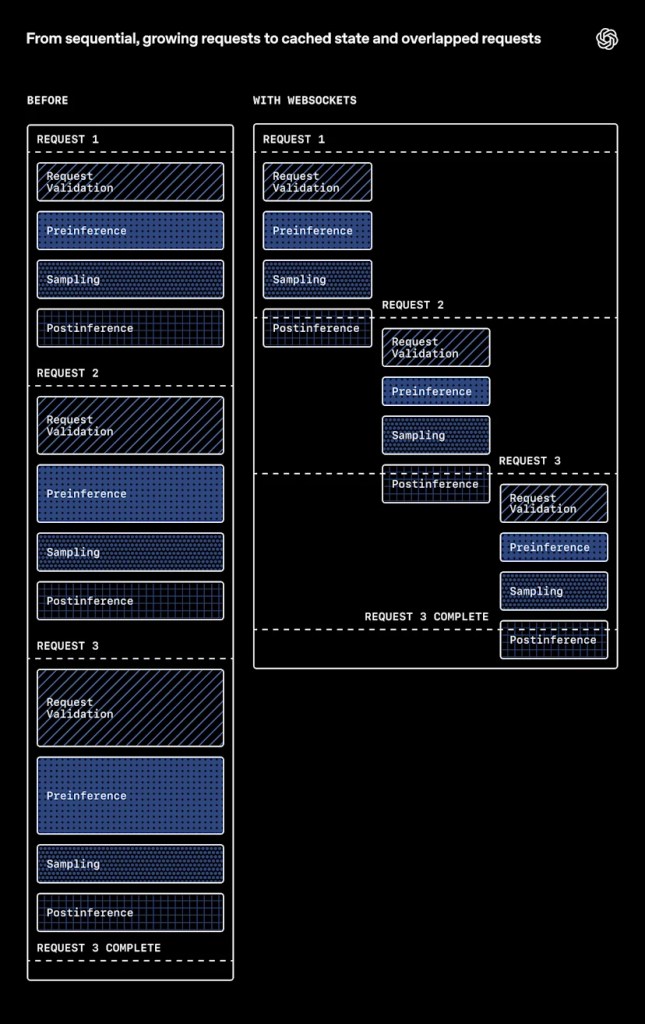
Dalle richieste sequenziali e crescenti allo stato memorizzato nella cache e alle richieste sovrapposte, OpenAI
Tuttavia, ci sono vincoli architetturali da considerare. Il caching in-memory funziona solo su connessioni persistenti: architetture serverless con cold start frequenti — comuni in ambienti cloud italiani come Aruba o Register — potrebbero non beneficiarne immediatamente. In questi casi, vale la pena valutare l'uso di container long-running o funzioni con provisioned concurrency per massimizzare il guadagno.
Un'altra implicazione pratica riguarda i costi. Riducendo il numero di chiamate ridondanti e il lavoro di tokenizzazione ripetuta, WebSocket mode può abbassare il consumo computazionale lato server — e, di riflesso, i costi operativi per chi gestisce volumi elevati di richieste. Per startup e PMI italiane che scalano prodotti basati su AI, questo fattore potrebbe pesare più della pura latenza.
Infine, il timing: WebSocket mode è già disponibile in produzione, ma l'integrazione richiede aggiornamenti agli SDK e test di regressione. Per chi ha roadmap di rilascio nel primo trimestre 2026, pianificare l'upgrade ora evita di dover gestire due code di manutenzione simultanee più avanti.
Per i team di sviluppo italiani che già usano le API OpenAI, l'upgrade a WebSocket mode richiede modifiche minime al codice — ma va pianificato con attenzione: il caching in-memory funziona solo su connessioni persistenti, quindi architetture serverless con cold start frequenti potrebbero non beneficiarne immediatamente
Per scoprire nuovi termini o approfondirli, visitate il nostro Glossario AI.
Fonte:
OpenAI, Speeding up agentic workflows with WebSockets in the Responses API , 22 aprile