

Un modello linguistico addestrato esclusivamente su dati sintetici generati da simulatori fisici ha migliorato le sue prestazioni alle Olimpiadi Internazionali di Fisica (IPhO) di 5-10 punti percentuali — senza aver mai visto un problema di fisica reale durante il training. Il risultato, pubblicato su arXiv il 13 aprile 2026 da ricercatori di Carnegie Mellon University e Lambda, ridefinisce il problema: il vero collo di bottiglia del ragionamento fisico AI non è la capacità dei modelli, ma la scarsità dei dati su cui allenarli.
Buona parte del progresso nei sistemi di ragionamento fisico AI — da DeepSeek-R1 in poi — si è basata sull’abbondanza di coppie domanda-risposta disponibili su internet. Questo funziona bene per la matematica, dove le risorse sono vaste e strutturate. Per la fisica e le scienze empiriche il quadro è opposto: meno dell’1% degli 800.000 esempi di training di DeepSeek-R1 riguarda argomenti STEM. Il paper di CMU propone una risposta concreta a questo vuoto: usare i simulatori fisici come generatori infiniti di supervisione verificabile, senza annotatori umani e senza dati internet. Per chi segue le applicazioni AI nel campo scientifico, è il cambio di paradigma più sostanziale degli ultimi mesi.
Sim2Reason e il ragionamento fisico AI: come funziona la pipeline
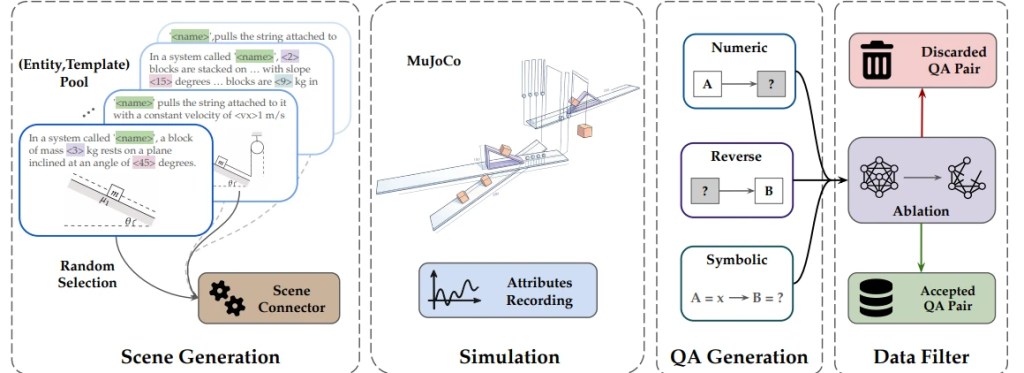
Sim2Reason è una pipeline che trasforma un motore fisico in una fabbrica automatizzata di dati di training. Il processo si articola in quattro stadi.
Il primo è la generazione delle scene. I ricercatori hanno progettato un linguaggio specifico di dominio (DSL) che descrive scenari fisici in modo strutturato e componibile: carrucole, masse, piani inclinati, sistemi molla-massa, collisioni, orbite. Il DSL separa i parametri fisicamente rilevanti — la massa di un blocco, l’angolo di inclinazione — da quelli che non cambiano il ragionamento sottostante, come la lunghezza di una corda. Questo permette di generare milioni di scene fisicamente coerenti senza intervento umano.

Il secondo stadio è la simulazione in MuJoCo, motore fisico standard in robotica. Per ogni scena, il sistema registra traiettorie temporali di grandezze fisiche: velocità, accelerazione, forze, energia, momento angolare. Le sequenze instabili — un blocco che fuoriesce dal piano, una collisione non modellata — vengono identificate e troncate automaticamente.
Il terzo stadio produce le coppie domanda-risposta in tre modalità: numerica (dato uno stato iniziale, calcola la velocità al tempo t), inversa (dato uno stato finale, inferisci il parametro mancante) e simbolica (esprimi il risultato in forma chiusa). Il quarto stadio filtra le domande che ammettono scorciatoie: se la risposta corretta è invariante rispetto alla rimozione di un’entità dalla scena, la domanda viene scartata. Circa il 15% dei dati generati viene eliminato in questo passaggio — e senza questo filtro i guadagni si dimezzano.
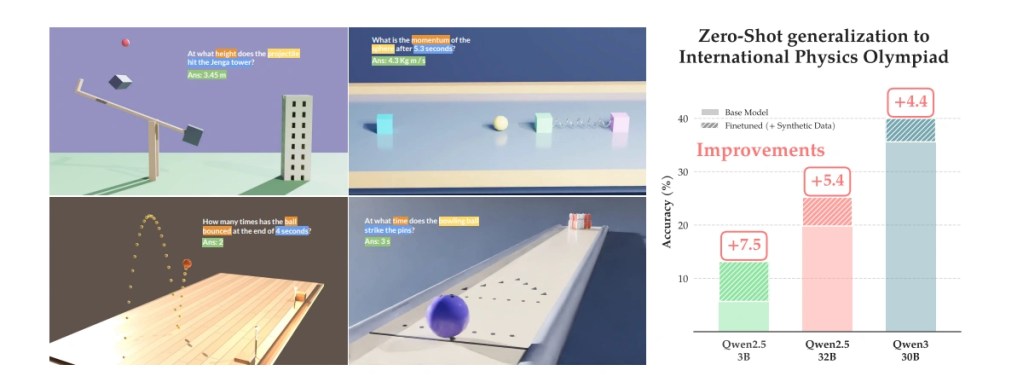
Il training usa RLVR — Reinforcement Learning with Verifiable Rewards — in cui il modello riceve un segnale di ricompensa positivo solo se la risposta finale rientra entro il 5% di errore relativo dal valore simulato. L’alternativa testata, il fine-tuning supervisionato (SFT) su 200.000 esempi, migliora di 2 punti in distribuzione ma peggiora di 3,9 punti su IPhO: l’ottimizzazione su dati statici comprime il ragionamento invece di espanderlo. Con RLVR e dati sintetici, Qwen2.5-32B guadagna invece 5,4 punti su IPhO e 17,9 punti su JEEBench.
“Training solely on Sim2Reason data improves zero-shot performance on IPhO mechanics problems by 5–10 percentage points across 3B to 32B model scales.” — arXiv:2604.11805, CMU / Lambda, aprile 2026
Il confronto diretto con modelli addestrati su dati reali curati è altrettanto significativo. Su IPhO, Sim2Reason con Qwen3-30B raggiunge il 40,0% contro il 38,6% di Prime P1, modello addestrato su oltre 5.000 problemi olimpionici reali selezionati da esperti umani. La qualità del segnale di supervisione batte la provenienza dei dati.
Il paper non nasconde che:
La copertura attuale di Sim2Reason si concentra quasi interamente sulla meccanica classica: cinematica, dinamica rotazionale, collisioni, gravitazione, con qualche incursione nell’elettromagnetismo di base. Termodinamica, ottica, meccanica quantistica e fisica dei fluidi sono fuori scope. I guadagni misurati su IPhO si riferiscono a un sottoinsieme di 77 domande di meccanica, non all’intera competizione.
I miglioramenti sui ragionamenti simbolici e inversi sono più modesti rispetto a quelli sulle domande numeriche, che restano il formato di training predefinito. La correlazione tra accuratezza sui dati sintetici e performance su IPhO (Spearman ρ = 0,79) è alta ma non perfetta: i problemi olimpionici reali introducono intuizioni geometriche e passaggi concettuali che il simulatore non cattura sistematicamente.
C’è poi una tensione strutturale che il paper affronta solo parzialmente: a che punto il modello smette di imparare fisica e comincia a imparare a navigare la struttura specifica del DSL? Il filtro shortcut mitiga il problema, ma non lo risolve per le domande che richiedono ragionamento sui vincoli del sistema, non solo sulle sue traiettorie. Estendere la pipeline a nuovi fenomeni richiede inoltre di aggiungere entità al DSL e reimplementarle nel simulatore: il bottleneck del domain engineering si sposta, non scompare.
“A direct avenue for future work is to combine simulator-generated data with curated real-world QA to further improve robustness and coverage.” — arXiv:2604.11805, ibid.
Ragionamento fisico AI e STEM: le implicazioni per ricerca e industria in Italia
Chi monitora questo spazio da vicino sa che il paper di CMU risponde a una domanda che il settore si poneva da tempo senza una risposta operativa: come si scala il training per il ragionamento scientifico quando i dati internet sono saturi? La risposta — simulatori come generatori di supervisione verificabile — non è nuova in robotica, dove la tradizione sim-to-real è consolidata da anni. È nuova, e significativa, applicata al ragionamento linguistico su domande fisiche.
Per i laboratori e i centri di ricerca italiani che lavorano su modelli STEM — dai gruppi di machine learning nelle università tecniche alle startup che sviluppano strumenti per l’istruzione scientifica — Sim2Reason offre un blueprint replicabile: non servono dataset annotati da esperti umani, servono simulatori fisici e una pipeline DSL che li sfrutti sistematicamente. Il codice è pubblico su sim2reason.github.io.
Per chi valuta modelli di ragionamento scientifico, il paper introduce anche uno strumento di benchmarking scalabile. La correlazione misurata tra accuratezza sintetica e performance IPhO suggerisce che i dati generati dal simulatore possono funzionare come proxy affidabile per confrontare checkpoint e configurazioni di training, senza ricorrere ogni volta a benchmark reali costosi e lenti da espandere.
Il dato più stringente resta questo: Sim2Reason ha superato un modello addestrato su 5.000 problemi olimpionici reali usando soli 6.400 esempi sintetici, generati e verificati in modo completamente automatico. Nell’equazione tra quantità di dati, qualità del segnale e costo di annotazione, i simulatori hanno appena spostato l’equilibrio.
Per approfondire i dati: Solving Physics Olympiad via Reinforcement Learning on Physics Simulators