

NVIDIA ha rilasciato Nemotron OCR v2, modello OCR multilingua addestrato su 12,2 milioni di immagini generate sinteticamente senza una sola annotazione manuale: il tasso di errore normalizzato su coreano, russo e giapponese scende da valori compresi tra 0,56 e 0,92 a un range di 0,035–0,069. Il modello processa 34,7 pagine al secondo su una singola GPU A100 — 28 volte più veloce di PaddleOCR v5 nella configurazione server.
Il risultato è rilevante perché sposta il problema. Il bottleneck dell’OCR multilingua non è mai stato architetturale: è sempre stato il dato. Raccogliere e annotare milioni di immagini in sei lingue con bounding box a livello di parola, riga e paragrafo, più grafi strutturali di ordine di lettura, è economicamente proibitivo su scala industriale. Nemotron OCR v2 dimostra che una pipeline sintetica ben costruita elimina quel vincolo senza sacrificare la precisione su documenti reali.
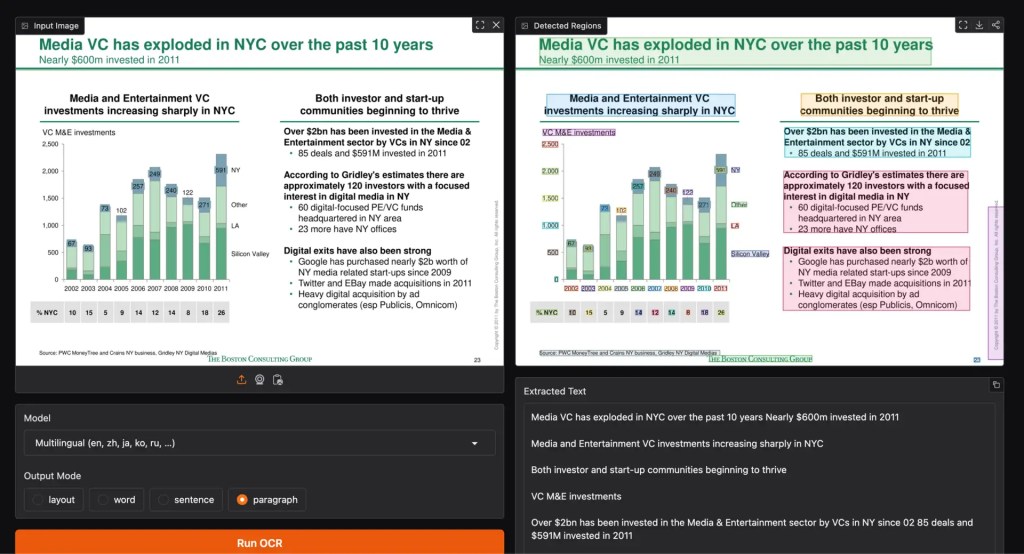
Nemotron OCR v2 in azione sulla demo Hugging Face: una slide BCG con layout a due colonne, grafico e testo sovrapposto. Il modello identifica le regioni testuali per tipologia e restituisce il contenuto in ordine di lettura corretto.
Come Nemotron OCR v2 risolve il problema dei dati sintetici
La pipeline combina due ingredienti: testo estratto da mOSCAR — corpus web multilingua con 163 sottoinsiemi linguistici — e un motore di rendering derivato da SynthDoG, esteso per generare annotazioni a tre livelli simultanei (parola, riga, paragrafo) più grafi di ordine di lettura. Questi grafi guidano il riconoscimento di layout complessi — tabelle, colonne multiple, testo verticale in giapponese e cinese — dove un approccio sequenziale top-to-bottom produrrebbe output illeggibile. Per ciascuna lingua sono stati usati tra 165 e 1.258 font open source; ogni immagine passa attraverso uno stack di augmentation che simula blur, distorsioni elastiche, variazioni di contrasto e rumore tipografico.
Il modello conta 84 milioni di parametri nella variante multilingua. L’architettura FOTS processa l’immagine una sola volta con un backbone condiviso (RegNetX-8GF), riutilizzando le stesse feature map per rilevamento, riconoscimento e analisi strutturale: un unico modello per cinque lingue simultaneamente, senza necessità di identificare la lingua in anticipo né di selezionare varianti specializzate. La variante English-only scende a 54 milioni di parametri e 40,7 pagine/secondo, grazie a un vocabolario ridotto da 14.244 a 855 caratteri.
La domanda che i benchmark non si pongono esplicitamente è questa: i dati sintetici reggono su documenti reali o solo su test generati con lo stesso renderer? Su OmniDocBench — materiale autentico in inglese, cinese e contenuto misto — Nemotron OCR v2 multilingual mantiene risultati competitivi a 34,7 pagine/secondo, contro 1,2 di PaddleOCR v5 e 1,5 di OpenOCR.
“The bottleneck was data, not architecture.” — Ryan Chesler, NVIDIA, Hugging Face Blog, 17 aprile 2026
Il dataset è rilasciato sotto licenza CC-BY-4.0; il modello sotto NVIDIA Open Model License.
Cosa cambia per le aziende italiane
Per chi gestisce flussi documentali multilingua — fatture internazionali, contratti, archivi storici scansionati — Nemotron OCR v2 abbassa concretamente la barriera di ingresso: precisione da modello specializzato, velocità da pipeline industriale, licenza open per uso commerciale. Un workflow che oggi elabora documenti in italiano o inglese può estendersi a fornitori asiatici o est-europei senza cambiare modello né infrastruttura.
Chi segue il settore sa che la vera implicazione non è il singolo modello: è la pipeline sintetica che lo ha generato. Aggiungere una nuova lingua richiede testo sorgente e font compatibili — zero interventi architetturali, zero annotazione manuale. Con mOSCAR che copre 163 sottoinsiemi linguistici e la famiglia Noto che supporta quasi ogni script Unicode attivo, la copertura universale è già un problema di risorse, non di metodo.
Per maggiori informazioni sul modello : Building a Fast Multilingual OCR Model with Synthetic Data
È possibile testare Nemotron OCR v2 direttamente nel browser: huggingface.co/spaces/nvidia/nemotron-ocr-v2