
Questo aprile 2026 ha segnato un punto di svolta silenzioso ma netto e tagliente nell'AI generativa. Anthropic rilascia Claude Opus 4.7, OpenAI risponde con Gpt-5.5. I due rispettivi rilasci non sono insoliti, entrambi i modelli puntano ad agire, non sono a rispondere. Ora se sviluppiamo un app , analizziamo dati o semplicemente scriviamo un paper ci troviamo davanti a due strade, quale modello utilizziamo? E per quale task? Senza incappare nel No-Value-Added Work.
Questo non è un articolo ma una guida pratica. Costruita su benchmark aggiornati, prompt testati e un analisi critica dei punti di forza reali dei due modelli. L'abbiamo scritta per chi domani mattina deve decidere se delegare un workflow a GPT-5.5 o affidare un'analisi editoriale a Opus 4.7. Senza tifoserie, con i numeri che servono e le regole che restano.
Quando usare Gpt-5.5 e Opus 4.7
| Benchmark | GPT-5.5 | Opus 4.7 | Vincitore |
|---|---|---|---|
| Coding | |||
| Terminal-Bench 2.0 | 82.7% | 69.4% | GPT-5.5 +13 pp |
| SWE-Bench Pro | 58.6% | 64.3% | Opus 4.7 +5.7 pp |
| Professionale | |||
| GDPval (knowledge work) | 84.9% | 80.3% | GPT-5.5 +4.6 pp |
| FinanceAgent v1.1 | 60.0% | 64.4% | Opus 4.7 +4.4 pp |
| OfficeQA Pro | 54.1% | 43.6% | GPT-5.5 +10.5 pp |
| Tool use | |||
| BrowseComp | 84.4% | 79.3% | GPT-5.5 +5.1 pp |
| MCP Atlas | 75.3% | 79.1% | Opus 4.7 +3.8 pp |
| OSWorld-Verified | 78.7% | 78.0% | Pareggio |
| Ragionamento accademico | |||
| GPQA Diamond | 93.6% | 94.2% | Pareggio |
| HLE senza strumenti | 41.4% | 46.9% | Opus 4.7 +5.5 pp |
| HLE con strumenti | 52.2% | 54.7% | Opus 4.7 +2.5 pp |
| FrontierMath Tier 4 | 35.4% | 22.9% | GPT-5.5 +12.5 pp |
| Ragionamento astratto | |||
| ARC-AGI-2 | 85.0% | 75.8% | GPT-5.5 +9.2 pp |
| Long context | |||
| MRCR 128K–256K | 87.5% | 59.2% | GPT-5.5 +28 pp |
| MRCR 512K–1M | 74.0% | 32.2% * | GPT-5.5 +42 pp |
* Dato riferito a Opus 4.6, non 4.7. Punteggi Opus 4.7 non disponibili per tutti i benchmark. Fonte: OpenAI, aprile 2026.
Batch e Flex pricing: metà del prezzo standard. Priority processing: 2.5× il prezzo standard. Context window API: 1M token.
-
Output strutturato JSON: chiedi sempre JSON per task con campi fissi (SEO, estrazione paper). Evita prose libera che GPT-5.5 espande inutilmente in assenza di vincoli di lunghezza.
-
Specifica sempre la lunghezza target: “~600 parole” o “max 3 frasi per sezione”. GPT-5.5 tende ad essere verbose se non vincolato esplicitamente.
-
Batch Pricing per task programmati: se l'articolo non è urgente, usa la Batch API a metà prezzo. Ideale per slot mattutini pre-pianificati (07:00/07:30).
-
Non usare GPT-5.5 Pro su task standard: è 6× più costoso in output ($180/M vs $30/M). Riservalo solo ad analisi matematiche o scientifiche molto dense.
-
Context window 400K in Codex: puoi passare interi paper PDF senza chunking. Evita però di caricare documenti irrilevanti “per sicurezza”: ogni token di input ha un costo.
-
Usa Fast mode con giudizio: 1.5× più veloce ma 2.5× il costo. Ha senso solo per task urgenti con deadline hard, non per produzione editoriale standard.
-
Non rimbalzare tra modelli sullo stesso draft: ogni nuovo contesto ricrea l'intero prompt. Scegli il modello prima di iniziare e portalo a fine task.
-
Evita chain-of-thought esplicita su task semplici: “pensa step by step” su query semplici gonfia l'output senza migliorarne la qualità. Usalo solo su ragionamento multi-step complesso.
Prompt B
— clicca per visualizzarlo
▾
You are an AI research assistant. Complete this task end-to-end without stopping for confirmation:
1. Summarize the key claims from this text in 5 bullet points with exact numbers:
"GPT-5.5 scores 84.9% on GDPval (vs 80.3% Claude Opus 4.7), 78.7% on OSWorld-Verified,
98.0% on Tau2-bench Telecom without prompt tuning, 88.5% on internal investment-banking
modeling tasks, and 54.1% on OfficeQA Pro (vs 43.6% Opus 4.7). API pricing: $5/1M input
tokens and $30/1M output tokens, with a 1M context window."
2. Identify the 2 benchmarks where the gap over competitors is largest.
3. Write a 2-sentence executive summary for a non-technical Italian manager.
4. Generate a JSON SEO package:
{"title": "≤60 chars IT", "meta": "~155 chars IT", "slug": "kebab-case", "alt": "image alt IT"}
Output: structured sections labeled 1–4, no preamble.
1. Key claims
- GPT-5.5 scores 84.9% on GDPval, compared with 80.3% for Claude Opus 4.7.
- GPT-5.5 scores 78.7% on OSWorld-Verified.
- GPT-5.5 scores 98.0% on Tau2-bench Telecom without prompt tuning.
- GPT-5.5 scores 88.5% on internal investment-banking modeling tasks.
- GPT-5.5 scores 54.1% on OfficeQA Pro, compared with 43.6% for Opus 4.7; API pricing is $5/1M input tokens and $30/1M output tokens, with a 1M context window.
2. Largest benchmark gaps over competitors
- OfficeQA Pro: +10.5 pp — GPT-5.5: 54.1% · Opus 4.7: 43.6%
- GDPval: +4.6 pp — GPT-5.5: 84.9% · Opus 4.7: 80.3%
3. Executive summary
GPT-5.5 mostra risultati superiori rispetto a Opus 4.7 nei benchmark in cui è disponibile un confronto diretto, con il vantaggio più ampio su OfficeQA Pro. Il modello combina prestazioni elevate, finestra di contesto da 1 milione di token e costi API dichiarati di $5 per 1M token input e $30 per 1M token output.
4. JSON SEO package
{
"title": "GPT-5.5: benchmark, costi e contesto",
"meta": "Sintesi dei risultati GPT-5.5: performance su benchmark, vantaggi rispetto a Opus 4.7, prezzi API e finestra di contesto da 1M token.",
"slug": "gpt-5-5-benchmark-costi-contesto",
"alt": "Grafico comparativo delle prestazioni GPT-5.5 sui principali benchmark AI"
}
Prompt C
— clicca per visualizzarlo
▾
Sei il redattore senior di AI Focus News. Hai davanti il system card ufficiale di GPT-5.5 (OpenAI, aprile 2026). Il tuo compito non è riassumere, ma fare giornalismo critico. Testo di riferimento: "GPT-5.5 is rated High under our Preparedness Framework for biological/chemical and cybersecurity capabilities. While GPT-5.5 didn't reach Critical cybersecurity capability level, our evaluations showed its cybersecurity capabilities are a step up compared to GPT-5.4. We are deploying stricter classifiers for potential cyber risk which some users may find annoying initially." Esegui questo ragionamento in tre passaggi espliciti: PASSAGGIO 1 — CLAIM VERIFICABILE Identifica l'unico dato numerico o threshold oggettivo presente nel testo. Se non esiste, dichiaralo esplicitamente. PASSAGGIO 2 — TENSIONE INTERNA Individua la contraddizione o il trade-off che OpenAI ammette implicitamente nel testo. Formulala in una frase netta senza opinione. PASSAGGIO 3 — ANGOLO EDITORIALE Proponi un titolo e un'apertura di 2 frasi per AI Focus News che: - Apra con la tensione del passaggio 2, non con l'annuncio del modello - Non usi le parole: potente, avanzato, rivoluzionario, innovativo, nuovo - Sia adatto a un lettore con background in sicurezza informatica Output: i tre passaggi etichettati, poi titolo e apertura separati.
PASSAGGIO 1 — CLAIM VERIFICABILE
Nel testo non compare alcun dato numerico. Non ci sono punteggi di eval, percentuali, delta quantitativi di capacità, false-positive rate dei classificatori, né soglie numeriche. Gli unici riferimenti oggettivi sono etichette categoriali del Preparedness Framework di OpenAI — “High” assegnato e “Critical” non raggiunto — più il confronto qualitativo con la versione precedente. Per un lettore tecnico, il testo è volutamente privo di ogni metrica che permetterebbe di misurare di quanto, in cosa e contro quale baseline le capacità cyber siano cresciute.
PASSAGGIO 2 — TENSIONE INTERNA
OpenAI dichiara nella stessa frase un incremento delle capacità cyber offensive rispetto alla generazione precedente e il fatto che i classificatori incaricati di mitigarlo sono — per parola dell'azienda stessa — un fastidio per gli utenti, destinato a essere tale inizialmente.
PASSAGGIO 3 — ANGOLO EDITORIALE
L'apertura si regge sulla collocazione di GPT-5.5 a un gradino dalla soglia che ne impedirebbe il rilascio, e sull'auto-denuncia dei classificatori come attrito temporaneo. Questi sono i due fatti che un professionista di sicurezza leggerà per primi nella system card.
Titolo: Cyber rating “High”, un gradino da “Critical”: OpenAI giustifica i filtri di GPT-5.5 prima ancora del rilascio
Apertura: A un gradino dalla soglia “Critical” che ne bloccherebbe il deployment, GPT-5.5 esce con rating “High” sia per capacità cyber sia per biologico-chimiche. Nella stessa frase in cui ammette un salto offensivo rispetto a GPT-5.4, OpenAI segnala che i classificatori più stringenti risulteranno fastidiosi agli utenti — giustificando l'attrito delle proprie mitigazioni prima ancora di descriverle.
Nota redazionale: prima della pubblicazione, verifica diretta della system card su openai.com e check della versione inglese letterale delle due citazioni (“High”/”Critical” e la formula sui classificatori), per blindare l'accuratezza del virgolettato.
| Dimensione | GPT-5.5 | Opus 4.7 |
|---|---|---|
| Completamento task | Tutti e 4 i punti, senza interruzioni | 3 passaggi + titolo e apertura, struttura rispettata |
| Precisione sui dati | Numeri corretti, ma ultimo bullet mescola dato benchmark e dato pricing | Dichiara esplicitamente l'assenza di metriche invece di cercarne dove non ci sono |
| Analisi critica | Non richiesta, non prodotta | Tensione interna estratta senza interpretare: “nella stessa frase” è una mossa editoriale precisa |
| Qualità SEO / titolo | Titolo corretto ma piatto, nessuna power word, nessuna tensione | Titolo pubblicabile direttamente, costruzione da professionista security |
| Iniziativa editoriale | Nulla oltre le istruzioni | Aggiunge spontaneamente una nota redazionale sul fact-checking — non era nel prompt |
| Velocità / struttura output | Risposta immediata, formato pulito, zero attrito | Leggermente più elaborato, richiede un task ben definito per non divagare |
GPT 5.5 Images 2.0 — Analisi pratica dei prompt
Foto 1 — Nightlife flash anni 2000

A causa della compressione di tipo webp , la foto perde di dettagli e qualità, Trovate sul nostro profilo X l'immagine nel formato originale.
Prompt:
A photorealistic snapshot portrait of two friends outside a venue at night, shot on a compact point-and-shoot camera with direct flash. Close subject distance, crisp foreground detail, deep shadow falloff, slightly raw spontaneous energy, nightlife atmosphere, and the unmistakable look of an early-2000s flash photograph.
Cosa funziona
- Estetica coerente
Il modello coglie bene il linguaggio visivo “early-2000s flash”: pelle leggermente sovraesposta, sfondo buio, contrasto duro. - Gestione della luce
Il direct flash viene interpretato correttamente: foreground nitido, shadow falloff marcato. - Feeling spontaneo
L'energia “snapshot” è credibile: framing non perfetto, pose naturali, vibe da uscita notturna reale.
Cosa non funziona
- Overfitting stilistico
A volte l'effetto Y2K è troppo “perfetto”, quasi simulato: manca quella casualità sporca delle vere point-and-shoot. - Texture pelle
In alcuni casi la pelle appare troppo uniforme o leggermente plastica sotto flash diretto. - Orecchio
L'orecchio della ragazza sulla sinistra è innaturale. - Dettagli ambientali generici
L'“outside a venue” può risultare poco specifico: insegna 19:30 ha una luce poco naturale e le scritte al di sono molto innaturali, contesto urbano non sempre credibili.
Limiti emersi
- Difficoltà nel ricreare imperfezioni autentiche (motion blur casuale, rumore reale da sensore vecchio).
- Tendenza a standardizzare il look nostalgia invece di variarlo.
- Background spesso meno curato rispetto ai soggetti.
Voto
8.5 / 10
Ottimo sul linguaggio fotografico, meno sulla casualità reale. Perfetto per visual storytelling, meno per simulazioni ultra-documentaristiche.
Foto 2 — iPhone snapshot con alieni

Anche qui purtroppo a causa della compressione di tipo webp , la foto perde di dettagli e qualità, Trovate sul nostro profilo X l'immagine nel formato originale.
Prompt:
A photorealistic iPhone photo of two aliens sitting at an outdoor cafe in late afternoon, taken casually by someone at the table. Half-finished drinks, uneven sunlight, relaxed posture, slightly imperfect framing, and the natural realism of a real everyday phone snapshot.
Cosa funziona
- Composizione casual credibile
Il framing imperfetto è reso bene: tagli strani, prospettiva da tavolo, sensazione “scattata al volo”. - Illuminazione naturale
La luce “late afternoon” con ombre irregolari è convincente e meno artificiale rispetto al caso flash. - Integrazione surreale
Gli alieni sono spesso integrati bene nel contesto realistico → buon equilibrio tra fantasy e quotidiano.
Cosa non funziona
- Design degli alieni incoerente
Cambia molto tra generazioni: stile, proporzioni e texture non sono stabili. - Interazione fisica debole
Bicchieri, mani, superfici: piccoli errori di contatto o prospettiva emergono. - Il dispositivo sul tavolo
Presenta il classico problema delle scritte irregolari. - Realismo plasticoso “quasi giusto”
L'immagine sembra reale a colpo d'occhio, ma perde credibilità a uno sguardo più lungo. Manca di sporcizia sul tavolo o all'interno di quella ciotolina, di piccoli dettagli che renderebbero la foto più vera.
Limiti emersi
- Difficoltà nel mantenere coerenza semantica su soggetti non reali.
- Problemi sottili di fisica implicita (ombre, contatti, profondità).
- Snapshot realism buono, ma non ancora indistinguibile da foto reale in contesti complessi.
Voto
7.6 / 10
Forte nel mood e nella composizione, ma cala quando deve rendere credibile qualcosa che non esiste.
Verdetto sintetico sulle immagini GPT-5.5
- Punto di forza principale: linguaggio fotografico (flash, smartphone, snapshot realism).
- Punto debole: coerenza fisica e imperfezioni autentiche.
- Quando usarlo: concept visivi, storytelling, prototipi creativi.
- Quando evitarlo: simulazioni fotografiche forensi o contenuti dove il realismo deve reggere analisi approfondita.
Confronto complessivo tra
In Conclusione
Gpt-5.5 e Claude Opus 4.7 sono strumenti con specializzazioni diverse, e la scelta migliore dipende dal compito. Se il task è agentico, richiede autonomia su contesti lunghi o un ragionamento astratto spinto, GPT-5.5 è oggi il riferimento. Se invece serve scrittura critica, aderenza a una linea editoriale, orchestrazione di tool via MCP o analisi finanziaria strutturata, Opus 4.7 resta insuperato.
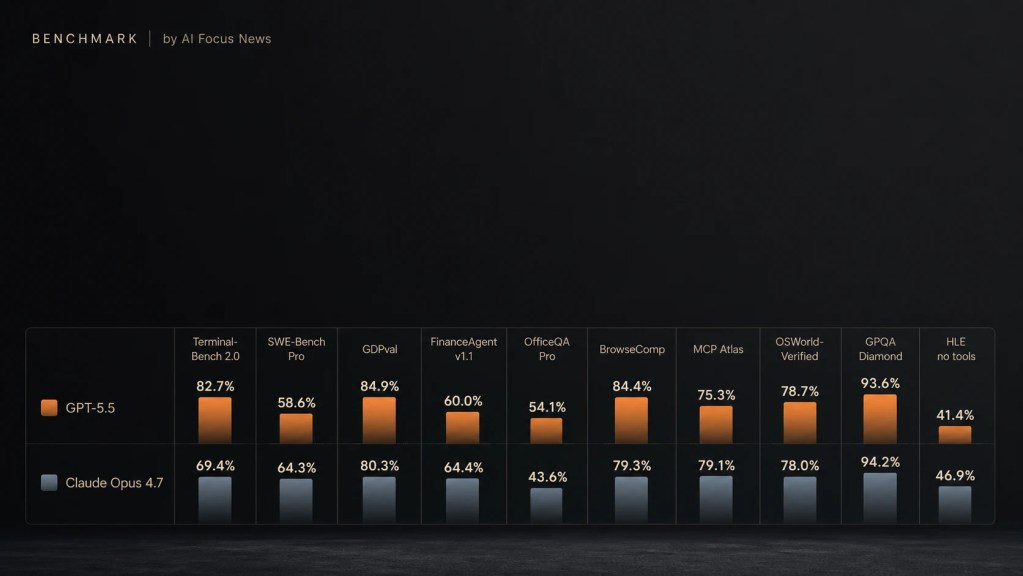
Confronto complessivo tra GPT-5.5 e Opus 4.7, fonte dei dati: OpenAI.
In Conclusione
Gpt-5.5 e Claude Opus 4.7 sono strumenti con specializzazioni diverse, e la scelta migliore dipende dal compito. Se il task è agentico, richiede autonomia su contesti lunghi o un ragionamento astratto spinto, GPT-5.5 è oggi il riferimento. Se invece serve scrittura critica, aderenza a una linea editoriale, orchestrazione di tool via MCP o analisi finanziaria strutturata, Opus 4.7 resta insuperato.