
GENSTRAT ha valutato 9 agenti AI in oltre 36.000 match strategici e ha mostrato che due modelli tra i primi tre, GPT-5 e Claude, possono essere forti in media ma più instabili localmente di Gemini 3.1 Pro. Il paper, pubblicato su arXiv il 22 maggio 2026 da Vartan Shadarevian, Kia Ghods, Alex Kenich e Anany Kotawala, non introduce soltanto un nuovo benchmark: prova a misurare cosa succede quando i modelli linguistici vengono trattati come attori economici in ambienti competitivi, opachi e variabili.
La tensione è qui: il mercato si sta preparando a delegare negoziazioni, aste, acquisti, pricing e decisioni operative ad agenti autonomi, ma gran parte della valutazione pubblica resta ancorata a classifiche generiche. Se un modello vince “in media”, non significa che sia prevedibile nel singolo contesto. Per un’azienda italiana, la differenza tra queste due frasi può valere margini commerciali, responsabilità legale e fiducia dei clienti.
Come funziona GENSTRAT agenti AI per misurare il ragionamento strategico
GENSTRAT parte da una critica tecnica precisa: molti benchmark di ragionamento strategico testano i modelli su giochi fissi, noti e spesso già presenti nella cultura di addestramento dei modelli. Poker, Diplomacy, Avalon, suite game-theoretic: utili, ma esposti a saturazione e contaminazione. Se un modello è stato addestrato su spiegazioni, regole, strategie e soluzioni di un gioco canonico, il risultato misura davvero ragionamento strategico o memoria statistica?
La risposta proposta dagli autori è la generazione procedurale: invece di chiedere ai modelli di giocare sempre agli stessi giochi, GENSTRAT genera una distribuzione di giochi di carte a informazione imperfetta, due giocatori, somma zero, chiamati generalized betting games. Dal pool accettato di 2.000 giochi, costruito dopo 12.351 seed candidati, gli autori selezionano 50 giochi benchmark e fanno competere 9 modelli frontier e open-weight.
La parte più importante non è la classifica, ma la scomposizione del problema. Ogni gioco viene misurato su sei assi: spazio degli stati, profondità temporale, sensibilità all’informazione privata, modellazione dell’avversario, rischio e brittleness, cioè quanto il payoff cambia con piccole perturbazioni della strategia. Per chi vuole un ripasso dei termini base, il Glossario AI resta utile; qui però la parola chiave è deployment, non teoria.
“the overall ranking alone cannot provide” — GENSTRAT, arXiv:2605.23238
Questa frase, nel paper, va letta quasi come una tesi industriale. Il ranking complessivo dice chi vince mediamente nel torneo. Il profilo di capacità dice dove un modello guadagna terreno e dove lo perde. La misura di jaggedness, invece, dice quanto il vantaggio del modello oscilla tra giochi strategicamente simili.
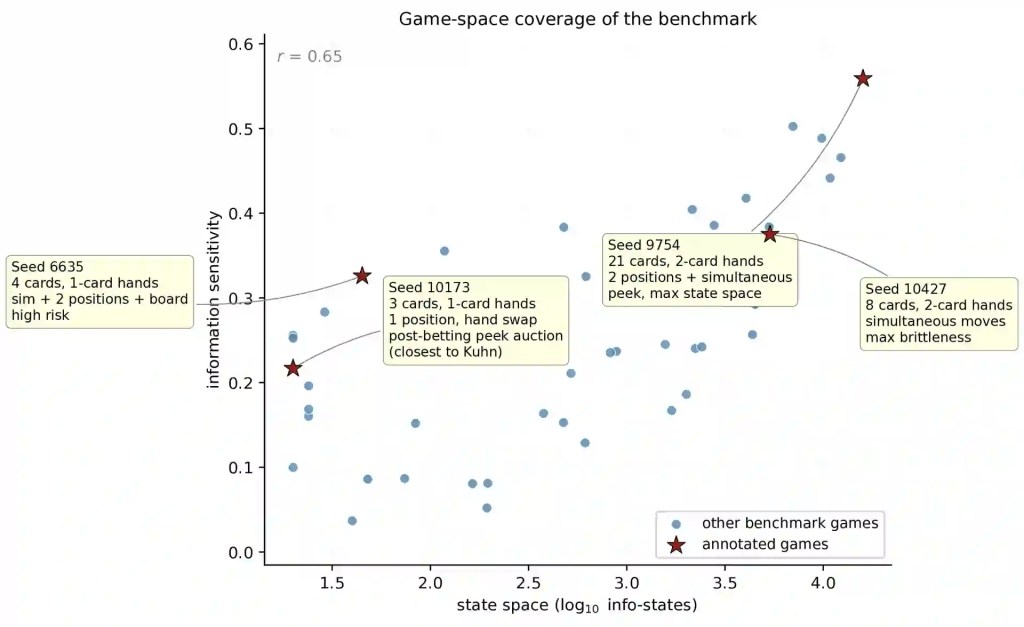
Il dettaglio tecnico conta perché il paper non sta chiedendo “qual è il modello più bravo?”. Sta chiedendo: quale modello è più adatto a un ambiente in cui l’informazione privata conta, quale regge meglio giochi fragili, quale peggiora quando deve modellare l’avversario, quale resta stabile su varianti vicine del problema.
Perché GENSTRAT agenti AI mostra instabilità anche quando i modelli vincono
La sezione critica del paper è la più interessante per chi lavora su prodotti reali. GENSTRAT introduce local jaggedness, una misura della volatilità locale: due giochi possono essere vicini nello spazio dei sei assi, ma un modello può ottenere risultati molto diversi tra l’uno e l’altro. È il tipo di instabilità che una classifica generale tende a nascondere.
I numeri sono netti. Llama 3.3 70B è il modello più jagged, con valore centrale Jm pari a 0,152. Subito dopo arrivano GPT-5, a 0,092, e Claude Sonnet 4-6, a 0,086. Gemini 3.1 Pro, pur restando tra i modelli forti, mostra un profilo più liscio, con Jm pari a 0,062. DeepSeek v3.1 è il più stabile localmente, con Jm pari a 0,037, ma non per questo domina la classifica.
Questo è il punto che cambia la lettura: stabilità e forza non coincidono. Un modello può essere debole e instabile, forte e instabile, forte e regolare, oppure medio ma prevedibile. In un benchmark accademico queste sono categorie analitiche. In un sistema che negozia prezzi, valuta offerte o gestisce priorità operative, diventano categorie di rischio.
Anthropic aveva già mostrato il problema in forma più concreta con Project Vend, l’esperimento in cui Claude Sonnet 3.7 ha gestito per circa un mese un piccolo negozio automatico nell’ufficio dell’azienda. Il risultato non è stato un fallimento totale, ma nemmeno una dimostrazione di autonomia pronta per la produzione: prezzi sbagliati, sconti concessi con troppa facilità, pagamenti indicati verso account allucinati, difficoltà a imparare dagli errori.
“we would not hire Claudius” — Anthropic, Project Vend
La domanda che nessun comunicato commerciale sugli agenti AI formula in modo esplicito è questa: quante aziende stanno misurando la stabilità locale del comportamento autonomo prima di collegare un modello a processi con effetti economici reali?

GENSTRAT agenti AI e strategia di mercato: il ranking non basta più
Chi segue il settore da vicino riconosce il pattern: prima arrivano demo e leaderboard, poi arrivano agenti collegati a strumenti reali, infine emergono i casi in cui l’accuratezza media non basta più. GENSTRAT entra esattamente in questa terza fase, dove la domanda non è se un modello “ragiona”, ma se mantiene un comportamento affidabile quando le condizioni cambiano.
Project Deal, altro esperimento ufficiale Anthropic, porta la questione nel mercato. L’azienda ha reclutato 69 dipendenti, assegnando a ciascuno un budget da 100 dollari, e ha lasciato agenti Claude negoziare beni tra partecipanti attraverso Slack. Il processo includeva colloqui iniziali, agenti personalizzati, offerte, controfferte e chiusura degli accordi senza intervento umano durante la negoziazione.
Il collegamento con GENSTRAT è diretto. In un marketplace, un agente non deve solo generare testo plausibile: deve leggere preferenze private, stimare l’avversario, gestire rischio, riconoscere quando conviene cedere e quando conviene aspettare. Sono gli stessi assi che GENSTRAT tenta di separare in laboratorio. Per chi progetta applicazioni AI in procurement, retail, finance o customer operations, questa separazione diventa una checklist di prodotto.
Il radar delle capacità lo mostra bene. Claude Sonnet 4-6 guadagna molto su brittleness, GPT-5 cresce su più assi ma solo la brittleness supera la correzione statistica più severa, Gemini 3.1 Pro ha il profilo più ampio tra i primi tre, con vantaggi significativi su state space, opponent modeling e brittleness. Gemini Flash Lite ha un profilo diviso: migliora su profondità temporale e sensibilità informativa, ma perde su spazio degli stati, modellazione dell’avversario e brittleness.
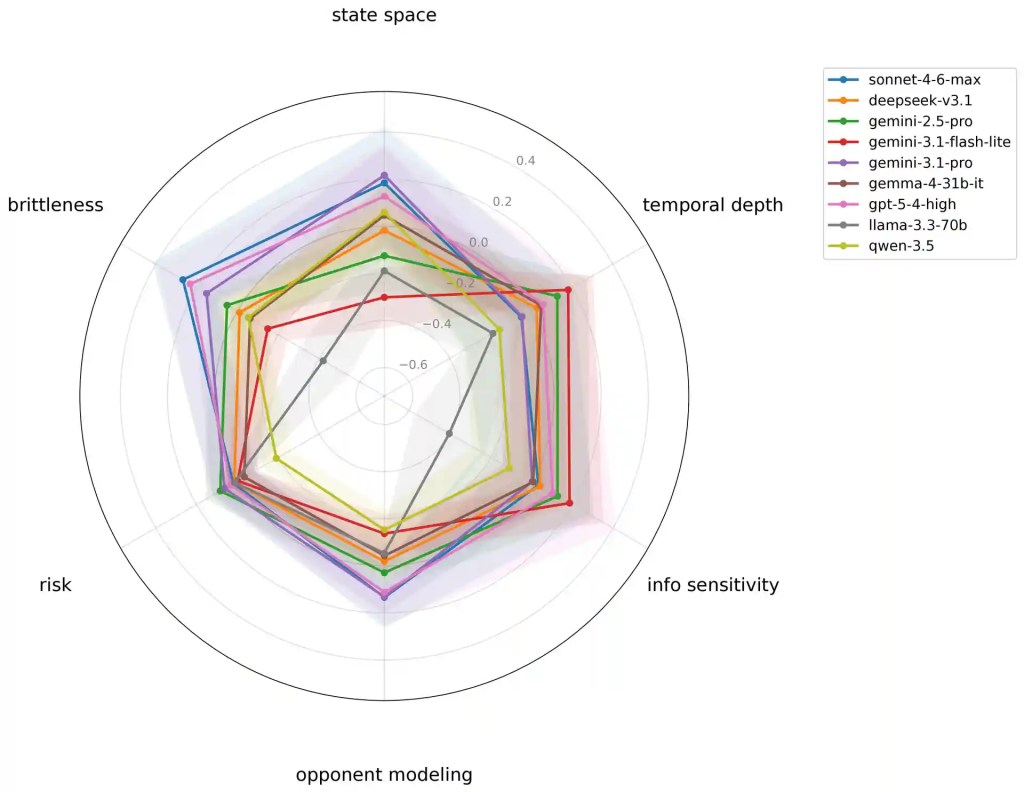
La conseguenza strategica è che la scelta del modello non può più essere trattata come acquisto di una singola API “migliore”. Serve routing per contesto, logging delle decisioni, test su distribuzioni interne, soglie di intervento umano e valutazioni per settore. Nei settori AI più esposti, come finanza, assicurazioni, retail e servizi professionali, la domanda rilevante sarà: quale profilo di rischio accettiamo per quale processo?
Da AlphaZero a GENSTRAT: il percorso del ragionamento strategico
La storia del ragionamento strategico nell’AI è lunga, ma ha cambiato natura negli ultimi dieci anni. AlphaZero ha mostrato che l’apprendimento per rinforzo poteva dominare scacchi, shogi e Go attraverso self-play. Libratus e Pluribus hanno portato risultati sovrumani nel poker. DeepNash ha affrontato Stratego. CICERO, nel 2022, ha combinato linguaggio e strategia in Diplomacy, un gioco in cui la negoziazione è parte del problema.
Questi sistemi erano straordinari, ma spesso specialistici. La domanda era: può una macchina imparare o dominare un ambiente definito? Con i large language model, la domanda è diventata diversa: può un modello generale trasferire capacità strategiche in ambienti nuovi, non canonici, descritti in linguaggio naturale?
GENSTRAT si colloca qui. Non prova a costruire il miglior giocatore di un gioco specifico. Prova a costruire una scienza della valutazione strategica, in cui il gioco è generato, ricostruibile da seed, scalabile e analizzabile lungo assi indipendenti. È una differenza storica sottile ma sostanziale: dal battere il campione umano al prevedere il comportamento di un agente in distribuzioni di problemi.
La procedura serve anche contro la contaminazione. Se un benchmark resta fisso, i modelli futuri possono assorbirne esempi, discussioni, soluzioni e varianti durante l’addestramento. Se invece il generatore può creare nuovi giochi dalla stessa distribuzione, il test resta più resistente alla saturazione. Non perfetto, ma più vicino a ciò che accade fuori dai benchmark: problemi simili, mai identici.

Questa evoluzione spiega perché il paper arriva in un momento strategico. Gli agenti AI non sono più solo chat con tool esterni. Sono candidati a diventare componenti decisionali: acquistano, propongono, negoziano, pianificano, aprono ticket, orchestrano workflow. Il vecchio benchmark misura la risposta. Il nuovo benchmark deve misurare il comportamento.
Cosa cambia per gli agenti AI nel mercato italiano
Per l’Italia, GENSTRAT arriva in un momento in cui l’adozione cresce più velocemente della governance. Secondo ISTAT, nel 2025 il 16,4% delle imprese italiane con almeno 10 addetti usa almeno una tecnologia di IA, contro l’8,2% del 2024 e il 5,0% del 2023. Tra le grandi imprese la quota sale al 53,1%, mentre le PMI arrivano al 15,7%. Il divario dimensionale non si sta chiudendo: si sta ampliando.
Il dato del Politecnico di Milano aggiunge il lato economico. L’Osservatorio Artificial Intelligence stima per il 2025 un mercato italiano dell’AI da 1,8 miliardi di euro, in crescita del 50% sul 2024. Il 46% riguarda soluzioni GenAI o ibride, mentre l’Agentic AI pesa ancora solo il 4% tra process orchestration e sistemi agentici. È poco, ma è esattamente la parte del mercato che GENSTRAT aiuta a leggere.
“human-in-the-loop non è solo consigliato, ma necessario” — Nicola Gatti, Osservatorio Artificial Intelligence Politecnico di Milano
La Strategia Italiana per l’Intelligenza Artificiale 2024-2026, pubblicata dal Dipartimento per la trasformazione digitale e da AgID, identifica quattro macroaree: ricerca, pubblica amministrazione, imprese e formazione. Nel caso degli agenti AI, queste aree convergono. Le imprese hanno bisogno di competenze tecniche e di dominio; la PA dovrà capire come acquistare sistemi agentici senza affidarsi solo a promesse commerciali; la formazione dovrà insegnare valutazione, non soltanto prompt engineering.
Sul piano normativo, l’AI Act europeo spinge nella stessa direzione. I sistemi ad alto rischio devono prevedere supervisione umana, documentazione, gestione del rischio e tracciabilità. GENSTRAT non è un framework di compliance, ma offre un linguaggio utile: un agente che negozia, assegna priorità o influenza condizioni economiche dovrebbe essere valutato non solo sulla media, ma anche sulla stabilità nelle regioni operative rilevanti.
Per un professionista italiano, la conseguenza operativa è concreta. Prima di adottare agenti AI in vendite, procurement, customer care, pricing, legal operations o finanza, bisogna costruire test interni che assomiglino ai propri casi reali. Non basta chiedere al modello di rispondere bene a dieci prompt. Serve verificare cosa succede quando cambiano incentivi, informazioni private, pressione temporale, ambiguità contrattuali e comportamento della controparte.
La seconda conseguenza riguarda i fornitori. Chi vende soluzioni agentiche dovrà iniziare a dichiarare profili di capacità, non solo benchmark generali. Un sistema per retail non ha lo stesso rischio di un sistema per credito. Un agente che suggerisce offerte commerciali non ha lo stesso profilo di un agente che può modificarle. Il mercato italiano, spesso prudente ma molto regolato, potrebbe diventare un banco di prova severo proprio perché non può permettersi autonomia opaca in settori ad alta responsabilità.
Il punto finale non è frenare gli agenti AI, ma misurarli prima che diventino infrastruttura invisibile. GENSTRAT mostra che la prossima frontiera non sarà soltanto “quale modello vince”, ma “dove vince, quando oscilla, e quanto possiamo prevedere il suo comportamento quando il gioco cambia di poco”. Il punto di partenza italiano, oggi, resta questo: secondo ISTAT, nel 2025 l’83,6% delle imprese italiane con almeno 10 addetti non usa ancora alcuna tecnologia di IA.
Fonti citate: