
Il paper arXiv 2606.06976, pubblicato il 5 giugno 2026, mostra che nel tool calling AI l'addestramento RL può portare gli errori sicuri dal 34,50% al 70,21% su Qwen3-4B-Thinking.
Per chi costruisce agenti aziendali, il problema non riguarda solo la qualità della risposta finale. Riguarda il momento in cui un modello decide se chiamare uno strumento, chiedere chiarimenti, rispondere direttamente o fermarsi. Quando quella decisione sbaglia, l'errore entra nel flusso operativo: una chiamata API inutile genera costi, una risposta diretta inventata bypassa una fonte verificabile, un tool sbagliato può contaminare tutti i passaggi successivi.
Il lavoro di Yijin Zhou, Linqian Zeng, Xiaoya Lu, Wenyuan Xie, Dongrui Liu, Junchi Yan e Jing Shao propone TRUST, acronimo di Tool-calling decision Reward with Uncertainty-Separated post-Training. La promessa non è rendere gli agenti “più autonomi” in senso generico. È più circoscritta e più importante: addestrare il modello a mantenere una separazione leggibile tra decisioni corrette e decisioni sbagliate, evitando che l'ottimizzazione lo renda troppo sicuro proprio quando sta sbagliando.
Come funziona il tool calling AI quando l'agente deve decidere
Nel tool calling AI, un large language model non produce soltanto testo. Riceve un obiettivo, osserva il contesto e sceglie se invocare uno strumento esterno: una funzione, un motore di ricerca, un database, un calendario, un ambiente di codice, un sistema CRM. Per una definizione più ampia dei termini tecnici, il rimando naturale è al Glossario AI, ma qui il punto è operativo: l'agente deve decidere quando agire.
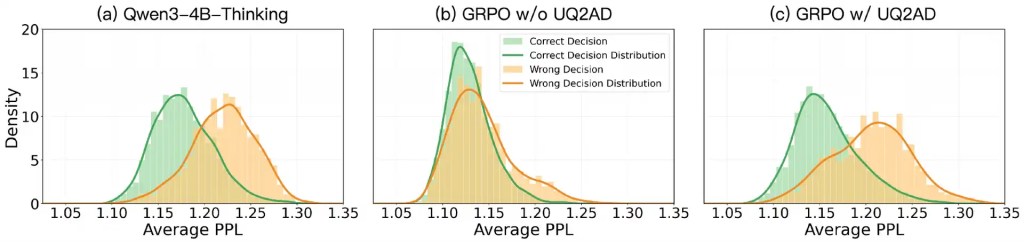
TRUST interviene su quella soglia decisionale. Gli autori osservano che molti metodi basati su reinforcement learning premiano l'azione corretta, ma non proteggono la struttura dell'incertezza. Il modello impara che alcune azioni hanno alto reward, però può perdere la capacità di distinguere internamente un'azione affidabile da una fragile. La metrica usata nel paper è la perplexity, trattata come proxy dell'incertezza: più bassa è la perplexity associata a una decisione, maggiore è la sicurezza del modello.
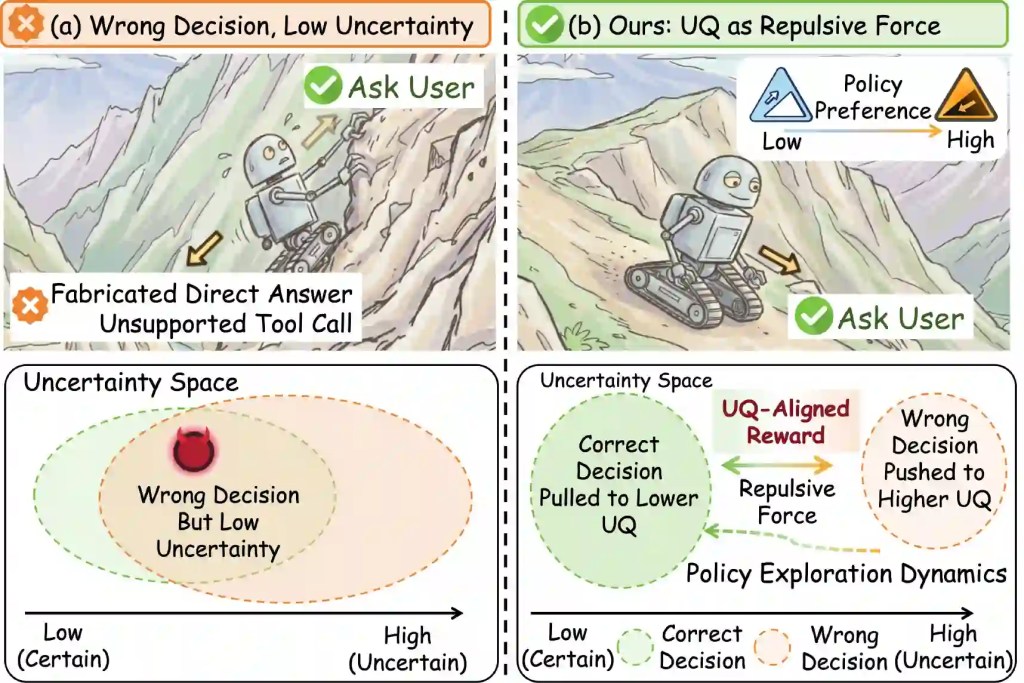
Il paper chiama il problema “Wrong Decision But Low Uncertainty”: decisioni sbagliate che il modello tratta come sicure.

La differenza tra RL tradizionale e TRUST sta nel reward. TRUST introduce un segnale che spinge il modello a mantenere bassa l'incertezza sulle decisioni corrette e più alta sulle decisioni scorrette o controfattuali. Gli autori descrivono questo meccanismo come una forza repulsiva: le decisioni giuste e sbagliate non devono collassare nella stessa regione di sicurezza.
Il framework lavora su due livelli. Al singolo turno, addestra il modello a classificare il momento giusto per chiamare un tool, rispondere, chiedere chiarimenti o astenersi. Sulle traiettorie multi-turn, aggiunge annotazioni leggere sui passaggi chiave, evitando di rietichettare ogni conversazione. Questo consente di combinare un reward di esito complessivo con un reward locale sulla qualità della decisione.
Il risultato tecnico più leggibile arriva da When2Call, benchmark progettato per misurare proprio quando un agente dovrebbe usare strumenti. TRUST migliora l'accuratezza normalizzata di 11,47 punti rispetto al checkpoint Qwen3-4B-Thinking e porta l'Acc Norm all'80,83%, con F1 all'82,84%. Su BFCL-V4, il modello post-addestrato raggiunge un Overall Score del 48,04% partendo da Qwen3-4B-Thinking, superando il modello base di 9,43 punti.
Il limite del tool calling AI: errori sicuri e strumenti chiamati male
La sezione più importante del paper non è quella dei miglioramenti. È quella che mostra cosa succede quando si ottimizza male. Dopo GRPO orientato alla decisione, la sovrapposizione tra decisioni corrette e sbagliate nella regione di bassa incertezza sale dal 34,50% al 70,21%. In termini pratici, il modello non sbaglia soltanto: sbaglia con maggiore sicurezza.
Questo è un rischio diverso dalle allucinazioni testuali tradizionali. Se un chatbot inventa una frase, l'utente può intercettarla nel testo. Se un agente invoca lo strumento sbagliato, passa parametri errati o decide di non chiamare una fonte quando dovrebbe, l'errore può diventare stato di sistema. Nei task multi-step, ogni decisione errata crea una superficie nuova per errori a valle.
I benchmark usati dagli autori cercano proprio questo punto. When2Call valuta se l'agente deve rispondere, chiamare uno strumento, chiedere informazioni o dichiarare che i tool disponibili non bastano. ToolSandbox misura tool use conversazionale e stateful, con scenari in cui l'agente deve gestire informazioni insufficienti o strumenti distrattori. BFCL-V4 valuta affidabilità del function calling, multi-turn e riconoscimento di funzioni irrilevanti.
L'AI Act richiede “automatic recording of events (logs)” per i sistemi ad alto rischio.
Il collegamento con la governance nasce qui. L'articolo 12 dell'AI Act parla di log e tracciabilità per sistemi ad alto rischio; l'articolo 13 chiede trasparenza sufficiente perché i deployer interpretino gli output; l'articolo 14 introduce supervisione umana proporzionata a rischio, autonomia e contesto d'uso. Un agente che chiama tool senza conservare un segnale affidabile sulla propria incertezza rende tutti e tre questi obblighi più difficili da tradurre in pratica.
Il paper resta prudente sui limiti. TRUST si basa soprattutto su perplexity, mentre gli autori indicano come direzione futura modelli di incertezza semantica o di traiettoria. Inoltre, gli esperimenti riguardano benchmark testuali con spazi d'azione predefiniti. La domanda che nessun annuncio commerciale pone è semplice: quante aziende stanno dando agli agenti accesso a strumenti reali senza misurare se il modello sa quando non deve usarli?
Perché il tool calling AI sposta il valore nello stack aziendale
Chi segue il settore da vicino riconosce il pattern: il valore si sta spostando dal singolo modello allo stack che lo circonda. Un agente utile non nasce solo da un LLM più capace. Nasce da tool definiti bene, permessi chiari, log leggibili, policy di fallback, valutazioni continue e capacità di interrompere l'automazione nei passaggi ad alto rischio.
OpenAI ha spinto in questa direzione con la Responses API e gli strumenti per agenti, presentando web search, file search e computer use come building block per applicazioni agentiche. Anthropic ha introdotto il Model Context Protocol, pensato per collegare modelli e fonti dati attraverso un'interfaccia standard. Google ha contribuito ad A2A, oggi ospitato come progetto open source, per far comunicare agenti costruiti su framework diversi.
OpenAI descrive le nuove API come base per “multiple tools and model turns”.
In questo contesto, TRUST aggiunge un tassello: non basta standardizzare il collegamento ai tool, bisogna addestrare il modello a decidere con incertezza calibrata. Il tool layer diventa una parte critica dell'architettura aziendale, al pari di identity, logging, observability e sicurezza applicativa. Per molte organizzazioni, soprattutto nei settori AI regolati, il problema non sarà scegliere tra agenti sì o no. Sarà stabilire quali azioni possano essere delegate, quali richiedano conferma umana e quali debbano restare fuori dal perimetro.
I numeri del paper aiutano a tradurre questa tendenza in criterio tecnico. Su ToolSandbox, TRUST in training turn-level ottiene 56,35 di Overall Score contro 39,37 di GRPO. Nella configurazione trajectory-level, raggiunge 68,28, superando il baseline CM2 di 7,07 punti e avvicinandosi al Qwen3-235B-A22B-Instruct, che segna 69,88. Il dato interessante non è solo il punteggio, ma il fatto che TRUST internalizza la logica decisionale nel modello, senza aggiungere latenza di inferenza come accade con metodi basati su prompting, riflessione o cicli trial-and-error.
Per un'azienda, questo trade-off pesa. Un sistema che migliora la qualità del tool calling senza moltiplicare passaggi di inferenza può ridurre costi e tempi. Ma trasferisce una responsabilità sul training e sulla valutazione: se il modello incorpora la policy di decisione nei pesi, il team deve sapere come l'ha ottenuta, dove fallisce e come monitorarla dopo il rilascio.
Da function calling ad agenti: il percorso che porta a TRUST
La storia del tool use nei modelli linguistici parte da un'idea semplice: il modello non deve conoscere tutto, deve sapere quando usare qualcosa fuori da sé. I primi sistemi di function calling hanno trasformato la risposta testuale in parametri strutturati. Il salto successivo ha portato agenti capaci di alternare ragionamento, chiamate esterne e osservazione dei risultati.
Con ReAct, Toolformer, ToolLLM e poi con benchmark come BFCL, la ricerca ha separato due problemi spesso confusi. Il primo riguarda la generazione corretta degli argomenti: se chiamo una funzione meteo, devo passare città, data e unità giuste. Il secondo riguarda la decisione preliminare: devo chiamarla davvero? Se il modello confonde questi due livelli, può apparire competente sui test semplici e fallire appena il contesto diventa ambiguo.
La fase 2024-2026 ha accelerato questa separazione. MCP ha proposto un protocollo comune per collegare modelli a fonti e strumenti. A2A ha spostato l'attenzione dall'agente isolato alla collaborazione tra agenti. Le API dei grandi provider hanno ridotto il costo di integrazione. Nel frattempo, la ricerca ha iniziato a studiare casi più vicini alla produzione: multi-turn, tool distrattori, strumenti non pertinenti, memoria, web search, parametri mancanti.
TRUST nasce in questa traiettoria. Gli autori non cercano di aggiungere un altro wrapper intorno al modello. Entrano nella fase di post-training e modificano il modo in cui il reward tratta l'incertezza. È una scelta tecnica coerente con il passaggio dagli agenti dimostrativi agli agenti operativi: se un sistema deve agire in ambienti reali, la sua sicurezza interna diventa parte della qualità del prodotto.
Il paper ammette che il lavoro resta dentro benchmark controllati. Gli agenti embodied, i workflow open-world e gli ecosistemi di tool dinamici introducono problemi più duri: azioni irreversibili, strumenti che cambiano, permessi contestuali, dipendenze tra sistemi aziendali. Però il contributo segna una direzione chiara. La prossima competizione non misurerà solo chi risponde meglio, ma chi sa agire, fermarsi e dichiarare incertezza nel momento giusto.
Cosa cambia per il tool calling AI nelle aziende italiane
Per l'Italia, il tema arriva in un momento preciso. Secondo l'Osservatorio Artificial Intelligence del Politecnico di Milano, nel 2025 il mercato italiano dell'AI ha raggiunto 1,8 miliardi di euro, in crescita del 50% rispetto al 2024. Il 46% del mercato deriva da soluzioni di GenAI o progetti ibridi, mentre l'84% delle grandi aziende ha acquistato licenze di almeno uno strumento di Generative AI.
Alessandro Piva sintetizza il punto: “Questo entusiasmo, però, impone di fermarsi a ragionare.”
Quel ragionamento riguarda soprattutto le applicazioni che passano da assistenza a esecuzione. Un copilota che suggerisce una risposta commerciale espone un rischio. Un agente che aggiorna un CRM, apre ticket, richiama documenti contrattuali, genera una raccomandazione finanziaria o muove dati sanitari espone un rischio diverso. Qui le applicazioni AI non vivono più nella demo: entrano nelle procedure.
ISTAT fotografa un'Italia ancora disomogenea. Nel rapporto Imprese e ICT 2025, il 16,4% delle imprese con almeno 10 addetti usa almeno una tecnologia IA, contro l'8,2% del 2024 e il 5,0% del 2023. Le grandi imprese passano dal 32,5% al 53,1%, mentre le PMI arrivano al 15,7%. Il divario dimensionale sull'adozione IA si allarga fino a 37 punti percentuali.
Il tool calling AI amplifica questo divario. Le grandi aziende possono costruire team di AI engineering, sicurezza, data governance e compliance. Molte PMI comprano strumenti pronti, spesso senza capacità interna di valutare log, permessi, failure mode e responsabilità. Se il mercato italiano importa agenti già integrati in suite aziendali, il rischio non sarà solo tecnologico. Sarà organizzativo: chi controlla che cosa l'agente può fare?
Per i professionisti italiani, il cambiamento tocca tre pratiche. La prima è la mappatura dei tool: ogni funzione esposta a un agente deve avere scopo, input, output, permessi e conseguenze documentate. La seconda è la valutazione per scenario: non basta testare la risposta finale, bisogna misurare false chiamate, mancate chiamate, parametri sbagliati e decisioni dirette non supportate. La terza è la supervisione: i passaggi ad alto impatto devono attivare revisione umana, non solo log tecnici conservati in un sistema che il legale non sa leggere.
TRUST non risolve da solo questi problemi. Offre però un segnale utile: se un agente può sbagliare con sicurezza crescente dopo l'addestramento, l'azienda deve trattare la calibrazione come requisito di progetto. Nel contesto europeo, questa esigenza incrocia logging, trasparenza, interpretabilità e human oversight. Nel contesto italiano, incrocia anche la maturità digitale delle imprese, la disponibilità di competenze e la distanza tra licenza software acquistata e infrastruttura AI governata.
Fonti citate
- Exploring Agentic Tool-Calling Decisions via Uncertainty-Aligned Reinforcement Learning , Yijin Zhou, Linqian Zeng, Xiaoya Lu, Wenyuan Xie, Dongrui Liu, Junchi Yan e Jing Shao, arXiv:2606.06976 [cs.AI], 2026.
- New tools for building agents , OpenAI, 11 marzo 2025.
- Introducing the Model Context Protocol , Anthropic, 25 novembre 2024.
- Agent2Agent (A2A) Protocol , A2A Project / Linux Foundation, consultato l'8 giugno 2026.
- Il mercato dell'AI in Italia cresce del 50% nel 2025, 1,8 mld di euro , Osservatorio Artificial Intelligence del Politecnico di Milano, febbraio 2026.
- Imprese e ICT – Anno 2025 , ISTAT, 2025.
- Article 12: Record-keeping , AI Act Service Desk, Commissione europea.
- Article 13: Transparency and provision of information to deployers , AI Act Service Desk, Commissione europea.
- Article 14: Human oversight , AI Act Service Desk, Commissione europea.