
Il benchmark scientifico DR3-Eval ha introdotto un protocollo rigoroso per valutare autonomamente 100 task di ricerca complessa, raggiungendo una stabilità nei dati grazie all'uso di “sandbox” statici che replicano la complessità del web senza la variabilità temporale delle ricerche live. Pervenuto da un team guidato dalla Nanjing University, questo studio rappresenta il primo attempt di creare un terreno di prova riproducibile per sistemi capaci di pianificare e sintetizzare informazioni in formati multimodali.
La distanza tra i comunicati promozionali dei giganti tecnologici e l'effettiva capacità operativa di un Large Language Model (LLM) è stata storicamente valutata tramite benchmark generici, spesso inadeguati per misurare la profondità dell'analisi. DR3-Eval tenta di colmare proprio questa lacuna: passare dal semplice “trovare una risposta” al “costruire un rapporto esperto”, integrando documenti utente eterogenei (PDF, immagini, video) e filtrando rumori informativi calcolatamente introdotti nell'ambiente di testing.
Architetture di Retrieval e Costruzione del Sandbox
DR3-Eval non si limita a somministrare domande: ricostruisce l'intero workflow di una ricerca professionale inversamente. I ricercatori partono dai documenti che contengono la soluzione vera e propria (il “ground truth”) e generano di conseguenza query che richiedono la consultazione simultanea di file caricati dall'utente e fonti esterne recuperate in un corpus controllato.
Questo metodo risolve la classica ambiguità dei test open-ended, garantendo che ogni task abbia un percorso risolutivo verificabile, pur mantenendo alti livelli di difficoltà cognitiva. Il sistema impiega meccanismi di Agentic-RAG iterativo: l'agente non effettua una singola query, ma pianifica, interroga il database locale, valuta la pertinenza dei risultati parziali e ricalibra la strategia fino a dieci volte per task.
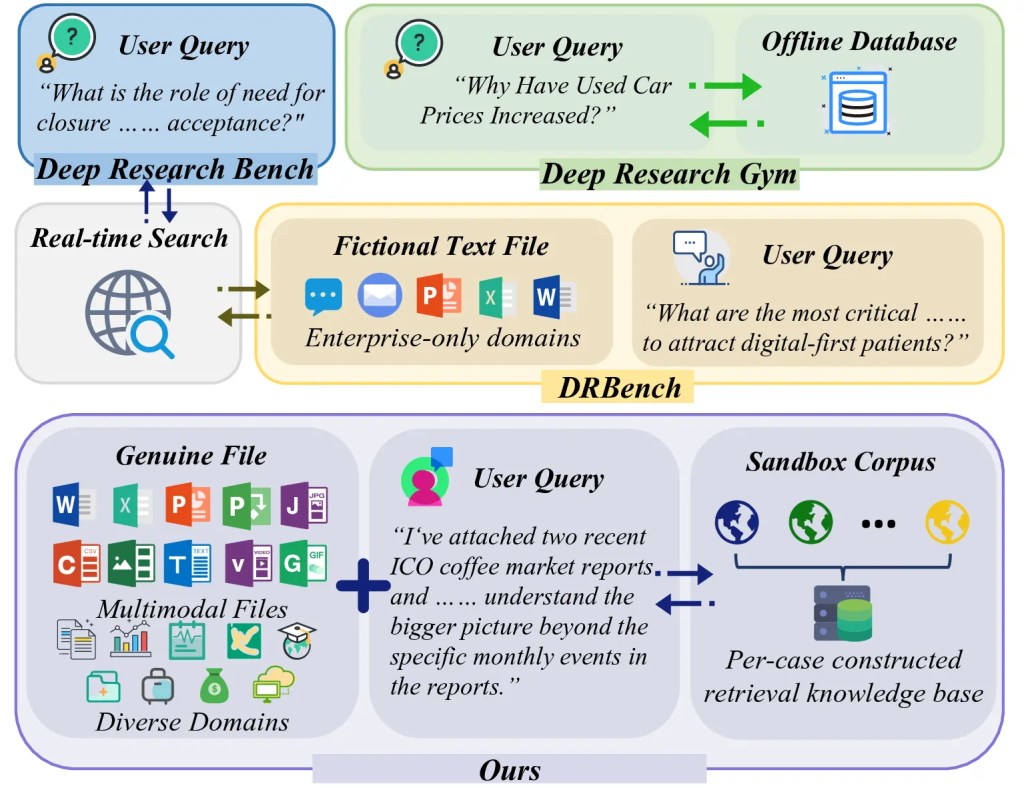
Confronto tra i benchmark di deep research. Dato un testo grezzo della query, Deep Research Bench esegue le query testuali tramite ricerca in tempo reale, mentre DeepResearchGym recupera informazioni da un database offline globale. DRBench incorpora file utente (modalità testuale) come input ma si affida alla ricerca in tempo reale e si concentra sul dominio aziendale. Al contrario, il nostro DR3-Eval elabora sia le query che i file all'interno di un corpus sandbox controllato su domini diversi.
Secondo gli autori del paper (Xie et al., Nanjing University, aprile 2026), la tensione fondamentale tra realisticità e controllabilità viene affrontata localizzando il corpus di retrieval in un sandbox statico e verificabile, così da consentire un'analisi sistematica e riproducibile delle strategie di ricerca degli agenti — senza dipendere dalla volatilità temporale del web aperto.
Questa struttura richiede ai modelli di possedere non solo competenze linguistiche, ma capacità metacognitive elevate: l'AI deve sapere cosa non sapere e navigare attivamente verso la risoluzione dell'obiettivo. Per questo motivo, il framework classifica le fonti presenti nel corpus in tre categorie distinte: Supportive (fondamentali per la risposta), Distractor (apparentemente rilevanti ma obsolete o parziali) e Noise (rumore semantico).
La domanda scomoda che i comunicati ufficiali ignorano è se questi miglioramenti architettonici servano realmente ad aumentare l'accuratezza del documento finale o se stiano semplicemente ottimizzando la quantità di token sprecati per arrivare allo stesso risultato.
I risultati sono stati validati su un pool di modelli top-tier, tra cui Claude Sonnet 4, GLM-4.7, GLM-4.6, GPT-4.1, Gemini 2.5 Pro e le versioni apicali di Qwen. Claude Sonnet 4 ha dominato le classifiche totali con un punteggio medio di 70.7 punti al setting 64k, seguito da GLM-4.7 (69.8) — modello sviluppato dalla cinese Zhipu AI — e GLM-4.6 (66.8). L'analisi rivela tuttavia pattern critici che sfidano l'ottimismo sull'affidabilità attuale degli assistenti intelligenti.

Prestazioni dei diversi LLM attraverso i diversi domini.
Criticità emerse: Hallucination e Fragilità dei Contesti Lunghi
I dati presentati nel paper sono illuminanti quanto inquietanti. Analizzando le cause di errore suddivise per tipologia (Retrieval Error, Reasoning Error, Hallucination), emerge un dato costante: l'hallucination rappresenta la categoria di errore numericamente dominante in tutti e cinque i modelli analizzati nel case study. Le proporzioni variano — dal 48% di GLM-4.7 fino al 77% di Qwen3-235B-A22B — ma in nessun caso questa tipologia cessa di essere la principale fonte di fallimento. Questo evidenzia un disaccoppiamento preoccupante tra la capacità di reperire i fatti e quella di rappresentarli fedelmente.
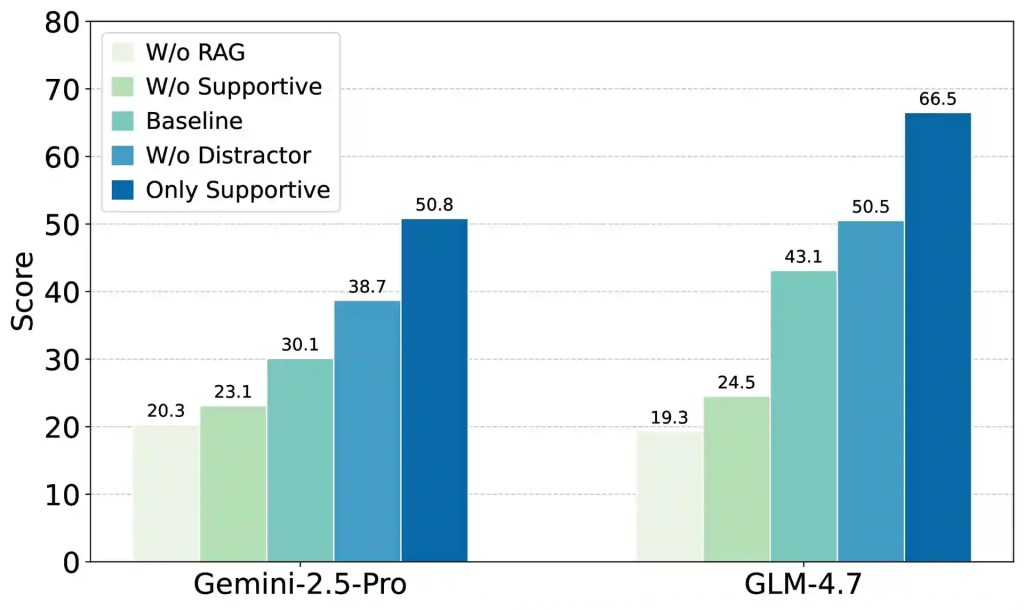
Analisi sull'efficacia del corpus sandbox.
In parole povere, anche quando un modello riesce a recuperare correttamente le informazioni rilevanti dal database statico (un punteggio di Information Recall medio-alto), fallisce massicciamente nella fase di sintesi, inventando fatti o citazioni che non supportano le sue affermazioni. Questo evidenzia un disaccoppiamento preoccupante tra la capacità di reperire i fatti e quella di rappresentarli fedelmente.
A ciò si somma il fenomeno del “loss in the middle” e il degrado prestazionale al crescere della complessità. Quando il contesto informativo viene ampliato da 64k a 512k token per aggiungere rumore di fondo, la precisione scende bruscamente in tutti i tested models. Non è un difetto di memoria, ma una limitazione intrinseca dell'attenzione sui contesti ultra-lunghi: il modello tende a confondersi tra le informazioni “supportive” e quelle “distrattrici” quando il volume di dati supera certe soglie critiche.
Un secondo punto debole riguarda la Factual Accuracy (FA) contro l'Instruction Following (IF). Modelli come GPT-4.1 hanno ottenuto punteggi eccellenti nel rispettare il formato richiesto e il tono (Instruction Following >80%), ma crollano nella correttezza fattuale (FA < 60%). Producono report che sembrano professionali, ben impaginati e completi a prima vista, ma che nascondono inesattezze sostanziali, rendendoli potenzialmente pericolosi in contesti professionali dove la forma vince sulla sostanza.
Implicazioni concrete per professionisti e PMI innovative
Per il panorama italiano, costituito da studi legali, istituti di consulenza e centri di ricerca accademica, questo benchmark offre criteri oggettivi per il procurement tecnologico. L'era dei tool “black-box” sta lasciando il passo alla necessità di auditare la catena del ragionamento (reasoning chain) prima ancora del singolo output.
L'elevata incidenza di hallucination suggerisce che l'adozione di sistemi autonomi per la generazione di report non possa avvenire senza un livello significativo di Human-in-the-loop. Per le aziende italiane, specialmente quelle operanti nel settore della Document Intelligence e compliance normativa, la priorità non deve essere solo l'automaticità del retrieval, ma la verifica delle citazioni fornite dall'AI.
L'ecosistema italiano dovrebbe cogliere l'opportunità offerta da dataset privati e altamente curati, simili alle sandbox statiche usate in DR3-Eval, per addestrare o fine-tune modelli aperti (come Llama o Mistral) sul dominio verticale specifico. Invece di affidarsi al web pubblico rumoroso, le grandi imprese potranno costruire knowledge-base interne verificate, trasformando un limite del benchmark in un vantaggio competitivo differenziante.
Il numero che riassume lo stato dell'arte non è la vittoria di un modello specifico, ma il fatto che persino i sistemi leader ottengano un punteggio massimo totale inferiore al 72%. Significa che siamo tecnicamente lontani dal raggiungere l'indipendenza operativa reale nella ricerca complessa.
Fonte: Xie et al., DR3-Eval: Towards Realistic and Reproducible Deep Research Evaluation, Nanjing University / M-A-P / Jiutian Research, arXiv:2604.14683, aprile 2026.