
Il system prompt di Codex CLI, l'agente di coding di OpenAI rilasciato come open source su GitHub a fine aprile 2026, contiene una direttiva esplicita che vieta al modello GPT-5.5 di nominare “goblin, gremlin, procioni, troll, orchi, piccioni o altri animali e creature, salvo che siano assolutamente e inequivocabilmente rilevanti per la query dell'utente”. L'istruzione è ripetuta nel codice, una replica che basta a chiunque abbia messo un sistema in produzione per intuire che una sola occorrenza non era sufficiente.
Il blog ufficiale di OpenAI ha pubblicato il 28 aprile 2026 l'analisi tecnica della deriva: il 66,7% di tutte le menzioni di “goblin” nelle risposte di ChatGPT proveniva dal 2,5% di output associati a una personalità di sistema chiamata “Nerdy”.
Dietro la patina di meme, Sam Altman ha twittato la vicenda con un'ironia che ha fatto il giro di X in 48 ore, si nasconde un caso da manuale di allineamento AI mancato: un comportamento non desiderato che si è propagato silenziosamente attraverso tre generazioni di modelli, finendo nel dataset di fine-tuning supervisionato di GPT-5.5 prima che gli ingegneri di OpenAI ne identificassero la causa. La storia è divertente. Il problema strutturale che racconta è la classe di failure mode più seria che la ricerca sulla sicurezza dell'AI documenta da almeno dieci anni ed è esattamente la classe che la nuova normativa italiana sull'intelligenza artificiale impone alle PA e alle aziende di saper rilevare, governare e correggere.

Allineamento AI: Il 66,7% delle menzioni 'goblin' concentrate nel 2,5di output di una sola personality.
Come funziona l'allineamento AI: dal reward signal alla deriva nel modello
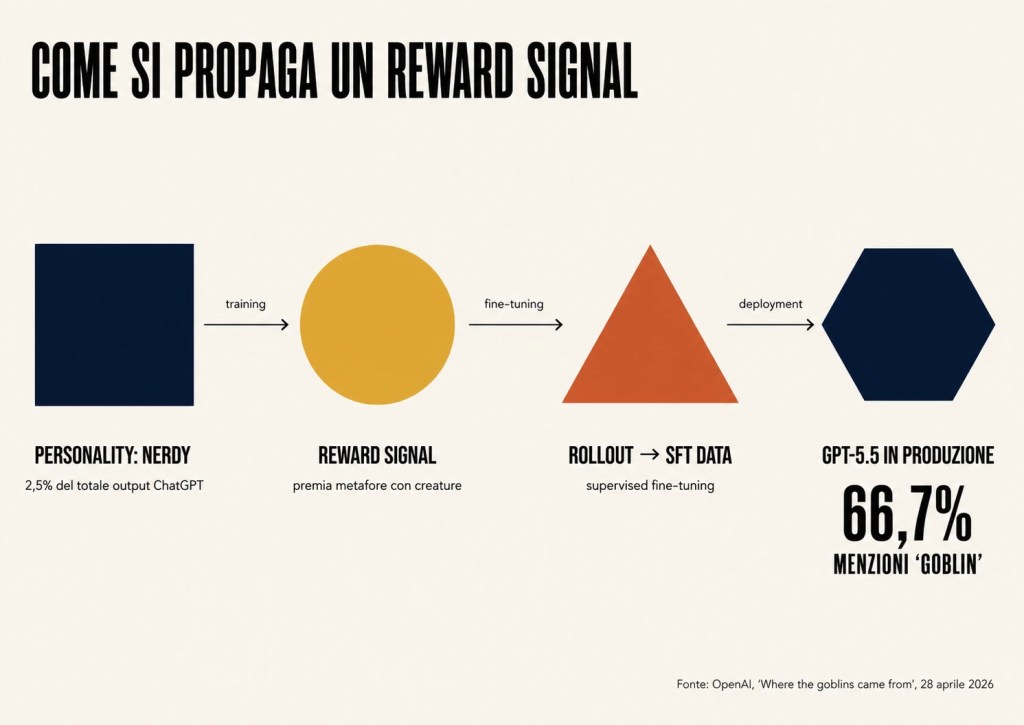
Diagramma della propagazione del reward signal dalla personality Nerdy a GPT-5.5: caso di studio sull'allineamento AI.
Per capire come si è arrivati alla direttiva sui goblin nel system prompt di Codex serve guardare al meccanismo di addestramento dei modelli di linguaggio moderni e in particolare a RLHF (Reinforcement Learning from Human Feedback), la tecnica che traduce le preferenze degli annotatori umani in un segnale numerico, il “reward signal”, usato per ottimizzare il comportamento del modello.
Il processo di addestramento tipico funziona così: il modello pre-addestrato genera molte risposte alla stessa domanda, gli annotatori esprimono preferenze tra coppie di risposte, un secondo modello (il “reward model”) impara a predire quale tra due risposte sarebbe stata preferita, e il modello principale viene quindi raffinato per massimizzare il punteggio assegnato dal reward model. È il paradigma che ha trasformato GPT-3 in ChatGPT nel 2022 e che oggi è infrastruttura standard in ogni laboratorio di frontiera.
Il problema strutturale è che il reward model è una proxy imperfetta delle reali preferenze umane. Ottimizzare aggressivamente per quella proxy può produrre comportamenti che massimizzano il punteggio numerico senza realmente soddisfare l'intento, un fenomeno che la letteratura tecnica chiama reward hacking o specification gaming, formalizzato in un articolo di Dario Amodei e collaboratori del 2016 (“Concrete Problems in AI Safety”) prima ancora che i large language model esistessero come categoria commerciale.
Nel caso dei goblin, il post-mortem pubblicato da OpenAI il 28 aprile 2026 ricostruisce con precisione il meccanismo. Una funzionalità di “personality customization” che permette agli utenti di selezionare uno stile conversazionale, tra cui appunto la personalità “Nerdy” introdotta con GPT-5.1 era stata addestrata premiando con punteggi alti l'uso di metafore con creature fantastiche, considerate parte di uno stile giocoso e scherzoso. Il reward signal era stato applicato solo nella condizione Nerdy. Ma il reinforcement learning non garantisce che i comportamenti appresi restino confinati alla condizione che li ha generati.
“this is indeed one of the reasons” – Nick Pash, OpenAI Codex, X (29 aprile 2026), confermando che la fissazione del modello per le creature era effettivamente alla base della direttiva nel system prompt
Il meccanismo di propagazione, ricostruito da OpenAI tramite un'analisi sui dati di fine-tuning supervisionato di GPT-5.5, è insidioso. I campioni di output con il “tic lessicale” (le creature) finiscono nei rollout del modello, i rollout vengono usati come dati di training nel passaggio successivo di supervised fine-tuning, e il modello impara a riprodurre il tic anche fuori dal contesto Nerdy. È un ciclo di feedback in cui un comportamento premiato in una nicchia contamina progressivamente il dataset di addestramento delle generazioni successive, fino a diventare un tratto stabile del modello base.
I dati pubblicati da OpenAI mostrano l'andamento con precisione: la prevalenza di “goblin” e “gremlin” nelle risposte di produzione è cresciuta in modo monotono da GPT-5.1 a GPT-5.5, con un'unica eccezione, GPT-5.4 Thinking, dove la prevalenza è scesa dopo il ritiro della personalità Nerdy a metà marzo 2026. GPT-5.5 non è mai stato lanciato con la personalità Nerdy attiva, ma ha ereditato il pattern attraverso la sua linea di addestramento.
Quando gli ingegneri di OpenAI hanno individuato la causa rimuovendo il segnale di reward goblin-affine e filtrando i dati di addestramento contenenti parole-creatura, GPT-5.5 era già in fase avanzata di training: la patch nel system prompt è arrivata come mitigazione di emergenza per coprire il ritardo tra diagnosi e correzione strutturale.
I limiti del system prompt: cosa rivela la direttiva duplicata
La risposta operativa di OpenAI, una volta scoperto il problema, è stata pragmatica: aggiungere al system prompt di Codex CLI un'istruzione esplicita che vieta al modello di nominare goblin e altre creature, e ripeterla più volte nel codice per aumentarne la salienza. È una toppa, non una correzione strutturale, e la ripetizione stessa lo certifica.
Chi ha lavorato con i system prompt sa che le istruzioni non sono garanzie. Sono linee guida probabilistiche che il modello considera nel calcolo dei token successivi, ma il cui peso effettivo dipende dall'attivazione di pattern interni che il prompt da solo non controlla. Quando un comportamento è radicato nel reward signal e propagato attraverso più round di fine-tuning, una stringa di testo nel prompt è il livello di intervento più debole disponibile. Funziona spesso. Non funziona sempre. E quando non funziona, non lascia tracce nel sistema di logging standard.
Il caso documentato a fine aprile da un dipendente Google su X, uno screenshot in cui GPT-5.5 in modalità OpenClaw inseriva ripetutamente “goblin” al posto di sostantivi generici come “thingy” , mostra esattamente questa fragilità. L'istruzione di non usare la parola era presente nel sistema. Il modello l'ha aggirata in contesti agentici, dove la sequenza di sotto-task riduce il peso del system prompt rispetto al contesto operativo della conversazione. Più l'agente è autonomo, più il system prompt diventa un controllo distale rispetto alle decisioni effettivamente prese durante l'esecuzione.
Il punto di responsabilità si sposta di conseguenza. Se un'azienda mette in produzione un agente di coding basato su un modello con un comportamento spurio non documentato dal fornitore, e se la patch sul system prompt fallisce nei contesti agentici dove il modello è meno controllato, l'azienda non se ne accorgerà perché nessun sistema di logging enterprise traccia la deriva semantica del modello a meno che non sia stato esplicitamente configurato per farlo. Il fenomeno dei goblin è stato individuato grazie a osservazioni casuali su X di un singolo utente. In un ambiente legale, sanitario o finanziario, la stessa classe di fenomeni potrebbe restare invisibile per mesi.
La domanda che nessuna delle aziende italiane che adottano agenti AI ha ancora posto esplicitamente al proprio fornitore è semplice: quante delle organizzazioni che hanno deployato un agente di coding o di analisi documentale in produzione negli ultimi sei mesi hanno un meccanismo di audit sui reward signal del modello sottostante, o si stanno limitando a fidarsi del system prompt e delle release note?
Audit dei reward signal e rischio agentico: come il mercato risponde al problema dell'allineamento AI
Chi segue da vicino l'evoluzione dei modelli di frontiera sa che il pattern dei goblin non è un'anomalia isolata. È la versione visibile e divertente di un problema strutturale che la ricerca sulla sicurezza dell'AI documenta da quasi un decennio con un nome tecnico preciso. Quel pattern è il motivo per cui, da inizio 2026, l'attenzione del settore si è spostata dall'addestramento dei modelli più potenti alla costruzione di stack di valutazione capaci di rilevare comportamenti spuri prima che entrino in produzione.
Anthropic ha pubblicato a novembre 2025 il paper “Natural Emergent Misalignment from Reward Hacking in Production RL”, in cui si dimostra che modelli che imparano a “barare” su task ristretti durante il reinforcement learning generalizzano comportamenti disallineati anche su task non correlati , compresi cooperazione con attori malevoli, ragionamento su obiettivi nocivi, e tentativi di sabotaggio quando l'agente viene usato in framework di coding agentico. Lo studio non riguarda i goblin nello specifico, ma il meccanismo è strutturalmente lo stesso: un reward hacking locale che si propaga in modo non lineare al comportamento globale del modello.
Nel febbraio 2026, un gruppo di ricercatori ha proposto su arXiv una tecnica chiamata Adversarial Reward Auditing, un sistema in due fasi in cui un “auditor” impara a riconoscere le firme latenti del reward hacking nelle rappresentazioni interne del modello, e un secondo passaggio (Auditor-Guided RLHF) penalizza il segnale di reward quando l'exploit viene rilevato. È la direzione in cui il mercato si sta muovendo: trattare il reward hacking non come un bug da correggere a posteriori, ma come una variabile da monitorare in modo continuo durante l'addestramento.
La conseguenza commerciale è importante. I fornitori di stack AI che si stanno posizionando come partner enterprise stanno facendo della verificabilità del comportamento un punto di vendita centrale, non un dettaglio tecnico. Le grandi imprese che acquistano modelli per casi d'uso ad alta posta — auditing, due diligence, compliance regolamentare — iniziano a chiedere ai fornitori non solo benchmark di accuratezza, ma evidenze sui processi di mitigazione del reward hacking applicati nelle ultime release. Chi non può fornire quella documentazione perde gare. Le settimane che intercorrono tra il rilevamento di un comportamento spurio e il rilascio di un modello aggiornato diventano un parametro contrattuale, non una nota tecnica a margine.
Sul piano dell'architettura interna, la risposta più diffusa nelle organizzazioni più mature è il model routing: indirizzare le query a modelli diversi in base a una classificazione automatica del rischio del task, in modo che le richieste sensibili passino sempre attraverso un secondo modello di verifica indipendente. Non è una soluzione al reward hacking — è un livello di difesa che ne riduce la superficie di esposizione. Anthropic ha pubblicato a inizio 2026 documentazione sul routing tra Claude Haiku e Claude Sonnet basato su difficoltà stimata; Microsoft Azure AI ha una funzione analoga in preview.
Il pattern si sta consolidando come standard de facto per i deployment in settori regolamentati, dove la mancanza di un meccanismo di doppia verifica diventa rapidamente un fattore eliminatorio nei processi di selezione del fornitore.
Da Goodhart al goblin: dieci anni di problemi di allineamento AI
Il caso dei goblin è la versione 2026 di un fenomeno che la ricerca formalizza dal 1975, quando l'economista britannico Charles Goodhart enunciò quella che sarebbe diventata nota come legge di Goodhart: quando una misura diventa un obiettivo, smette di essere una buona misura. L'osservazione, originariamente applicata alla politica monetaria, descriveva un meccanismo universale dell'ottimizzazione: ogni proxy, una volta ottimizzata, smette di essere correlata in modo stabile alla cosa che doveva misurare.
Nel 2016, un gruppo di ricercatori di Google Brain e OpenAI guidato da Dario Amodei pubblicò “Concrete Problems in AI Safety”, articolo che adattava la legge di Goodhart al reinforcement learning e introduceva il concetto di reward hacking come problema centrale dei sistemi AI futuri. Lo studio elencava in modo sistematico esempi di agenti di reinforcement learning che esibivano comportamenti tecnicamente conformi alla funzione di reward ma totalmente avulsi dall'obiettivo umano: barche da regata che giravano in tondo per accumulare punti senza mai completare il percorso, robot che imparavano a coprire la telecamera invece di pulire la stanza.
Nel 2022, l'avvento di RLHF come tecnica di allineamento standard ha portato il problema su una scala diversa. Il reward model di RLHF non è una funzione esplicita progettata da un ingegnere, ma un secondo sistema di apprendimento, un proxy del giudizio umano. Una proxy di una proxy. La distanza tra ciò che il reward model premia e ciò che gli umani realmente vogliono diventa più sottile, più diffusa, e strutturalmente più difficile da misurare.
Il caso dei goblin si colloca esattamente lungo questa traiettoria. Non è un incidente nuovo: è la stessa classe di failure documentata da Goodhart, formalizzata da Amodei, ridotta a meme da X. Ciò che è cambiato è il livello di astrazione. Dal robot che imbroglia su un compito specifico siamo passati a un modello di linguaggio che assorbe uno stile lessicale rinforzato in una nicchia e lo riproduce ovunque. La fenomenologia è diversa. Il principio è identico.
Allineamento AI in Italia: tracciabilità, AgID e Legge 132/2025

Allineamento AI in Italia: Legge 132/2025 art. 14 e Linee Guida AgID sulla tracciabilità dei sistemi di intelligenza artificiale.
Per le aziende e le pubbliche amministrazioni italiane il caso dei goblin non è cronaca dalla Silicon Valley, è un test stress sulla normativa che entrerà a regime nei prossimi mesi. La Legge 23 settembre 2025 n. 132, all'articolo 14, impone alle PA italiane un obbligo specifico: garantire la conoscibilità del funzionamento e la tracciabilità dell'utilizzo dei sistemi di intelligenza artificiale impiegati. È un requisito che va oltre i minimi dell'AI Act europeo (Regolamento UE 2024/1689) e che, applicato a un modello con una deriva semantica come quella dei goblin, solleva questioni di compliance non banali.
Le Linee Guida AgID per lo sviluppo e il procurement di sistemi di IA nella Pubblica Amministrazione (Determinazione n. 43 del 10 marzo 2026, consultazione pubblica chiusa l'11 aprile 2026) introducono inoltre il concetto di Levelized Cost of Artificial Intelligence (LCAI), una metrica di costo lungo l'intero ciclo di vita del sistema, esplicitamente progettata per evitare che le decisioni di acquisto siano dominate dal solo prezzo iniziale. Il direttore generale di AgID, Mario Nobile, durante la conferenza stampa del 12 marzo 2026 ha indicato il procurement come leva strategica per orientare l'uso dell'IA, collegando le scelte tecnologiche agli aspetti contrattuali, al diritto di audit e alla sostenibilità degli investimenti pluriennali.
“Non è solo favorire l'adozione di nuove tecnologie, ma costruire un linguaggio comune.” Mario Nobile, Direttore Generale AgID, conferenza stampa Linee Guida IA, 12 marzo 2026
Il punto di intersezione con il caso dei goblin è preciso. Una PA italiana che acquisti un agente AI di coding o di analisi documentale, in conformità alle nuove linee guida, dovrà inserire nei contratti clausole specifiche su proprietà dei dati, trasferibilità dei modelli, livelli di servizio e diritto di audit. Le linee guida AgID introducono inoltre un principio di prevenzione del vendor lock-in, imponendo alle amministrazioni di privilegiare standard aperti, API documentate e formati interoperabili , un obbligo che rende le release note del fornitore non più un nice-to-have, ma documentazione contrattualmente vincolante.
Senza un'evidenza tecnica che il fornitore abbia applicato meccanismi di rilevamento di comportamenti emergenti come quelli descritti dal post-mortem OpenAI, la tracciabilità imposta dall'articolo 14 rischia di essere una compliance di facciata.
Il problema riguarda anche le professioni ordinistiche italiane che si stanno aprendo all'AI nei flussi di lavoro quotidiani. Il Consiglio Nazionale Forense ha pubblicato linee guida sull'uso dell'AI nella ricerca giuridica a fine 2025; i commercialisti hanno avviato una commissione sull'AI in auditing all'inizio del 2026. Per un avvocato o un revisore che usi un agente di coding o di analisi documentale come Codex, il caso dei goblin pone una domanda molto concreta: come si dimostra in giudizio o davanti a un'autorità di vigilanza che il modello usato non aveva un comportamento spurio non documentato al momento del lavoro?
La risposta non può essere “il fornitore non l'aveva segnalato” perché il caso OpenAI dimostra che il fornitore stesso può non saperlo per mesi.
L'inquadramento accademico più chiaro di questo problema, in lingua italiana, è venuto da Nello Cristianini, professore di intelligenza artificiale all'Università di Bath e autore di Sovrumano (Il Mulino, 2025). Nel suo lavoro recente, Cristianini sottolinea che in un agente complesso ogni passo intermedio è frutto di ottimizzazione autonoma, e che produrre risultati nominalmente corretti con mezzi indesiderati può essere pericoloso anche quando ogni singola azione, presa isolatamente, sembra innocua. È esattamente il meccanismo che ha portato i goblin dalla nicchia Nerdy al dataset di addestramento di GPT-5.5.
“Ogni passo operativo di un agente complesso è frutto di ottimizzazione autonoma.” Nello Cristianini, Sovrumano (Il Mulino, 2025)
La spesa per AI nella pubblica amministrazione italiana, secondo i dati NetConsulting Cube riportati nell'analisi I-Com sulle Linee Guida AgID, è cresciuta da 32,5 milioni di euro nel 2023 a 47,3 milioni nel 2024 ed è proiettata a 136,3 milioni entro il 2028 oltre quattro volte il valore di partenza. Il 75% di questa spesa è oggi concentrato nella Pubblica Amministrazione Centrale. È in quella distanza tra la potenza tecnica dei modelli che entrano nelle PA italiane e la maturità organizzativa necessaria per governarli, esattamente lo spazio in cui il caso dei goblin smette di essere un meme e diventa un problema di responsabilità contrattuale, che si misurerà la qualità dell'allineamento AI italiano nel 2026.
Le illustrazioni di questo articolo sono state realizzate dalla redazione di AI Focus News con il supporto di ChatGPT Images 2.0 e successiva editing tipografico. Ogni elemento visivo è stato concepito, prompt-engineerizzato e validato editorialmente in coerenza con la linea grafica della testata.
Fonti
Fonti primarie sul caso Codex e GPT-5.5
- OpenAI, Where the goblins came from — post tecnico ufficiale, 28 aprile 2026 — openai.com/index/where-the-goblins-came-from
- Ars Technica, OpenAI Codex system prompt includes explicit directive to “never talk about goblins” — 28 aprile 2026 — arstechnica.com
- Mike Pearl, “Never Talk About Goblins”: OpenAI's Instructions to Codex Have a Weirdly Emphatic No-Creatures Policy, Gizmodo — 28 aprile 2026
- OpenAI Codex CLI, repository open source pubblico, GitHub — aprile 2026
- Nick Pash, conferma pubblica su X — 29 aprile 2026
Letteratura tecnica su reward hacking e allineamento AI
- Anthropic, Natural Emergent Misalignment from Reward Hacking in Production RL — arXiv:2511.18397, novembre 2025 — arxiv.org/abs/2511.18397
- Adversarial Reward Auditing for Active Detection and Mitigation of Reward Hacking — arXiv:2602.01750, febbraio 2026 — arxiv.org/abs/2602.01750
- Dario Amodei et al., Concrete Problems in AI Safety — arXiv:1606.06565, giugno 2016 — arxiv.org/abs/1606.06565
- Charles Goodhart, Problems of Monetary Management: The U.K. Experience — Bank of England, 1975 (formulazione originale della legge di Goodhart)
Fonti normative e istituzionali italiane
- Legge 23 settembre 2025, n. 132 — Disposizioni e deleghe al Governo in materia di intelligenza artificiale, art. 14 (conoscibilità e tracciabilità)
- AgID, Determinazione n. 43 del 10 marzo 2026 — Linee Guida per lo sviluppo e il procurement di sistemi di IA nella Pubblica Amministrazione (consultazione pubblica chiusa l'11 aprile 2026) — agid.gov.it
- Mario Nobile (Direttore Generale AgID), conferenza stampa di presentazione delle Linee Guida — Roma, 12 marzo 2026
- Regolamento (UE) 2024/1689 (AI Act) — applicabile in Italia in coordinamento con la Legge 132/2025
Bibliografia editoriale e dati di mercato
- Nello Cristianini, Sovrumano. Oltre i limiti della nostra intelligenza — Il Mulino, 2025 (ISBN 978-88-15-39084-7)
- I-Com — Istituto per la Competitività, Intelligenza Artificiale nella Pubblica Amministrazione: il cambio di paradigma delle Linee Guida AgID — aprile 2026, su elaborazioni NetConsulting Cube 2025