
Claude Opus 4.7, rilasciato oggi 16 aprile 2026, risolve il 13% in più di task di coding complessi rispetto al predecessore, triplica le attività portate a termine nei benchmark industriali su codebase in produzione e introduce una visione ad alta risoluzione che supera di tre volte i limiti dei modelli precedenti — il tutto allo stesso prezzo di listino: 5 dollari per milione di token in input, 25 in output.
Il rilascio, però, non è solo un aggiornamento di prestazioni. È il primo esperimento su larga scala con cui Anthropic testa i meccanismi di sicurezza che renderanno possibile, in futuro, il rilascio pubblico di Mythos — il modello più potente dell'azienda, attualmente riservato a una quarantina di aziende nell'ambito del Project Glasswing. Opus 4.7 è, nelle parole di Anthropic stessa, “il primo passo di una roadmap di evidenze”. Non il punto di arrivo.

Come funziona Claude Opus 4.7
Tre cambiamenti strutturali distinguono Opus 4.7 da Opus 4.6.
Il primo riguarda il self-verification: il modello identifica e corregge i propri errori logici durante la fase di pianificazione, prima di consegnare l'output. Il meccanismo non è nuovo nell'ecosistema AI, ma la sua implementazione in Opus 4.7 produce effetti misurabili: su CursorBench — il benchmark interno di Cursor per task di coding reali — il modello risolve il 70% delle attività contro il 58% del predecessore. Su Rakuten-SWE-Bench, la suite di test su codebase in produzione, Opus 4.7 chiude tre volte più task di Opus 4.6. Su un benchmark proprietario a 93 task di Linear, il miglioramento è del 13%, con quattro task che né Opus 4.6 né Sonnet 4.6 riuscivano a risolvere.
Il secondo cambiamento riguarda la visione ad alta risoluzione. Opus 4.7 accetta immagini fino a 2.576 pixel sul lato lungo — circa 3,75 megapixel, oltre tre volte rispetto ai modelli precedenti. L'upgrade è a livello di modello, non di parametro API: tutti gli utenti esistenti ricevono automaticamente la risoluzione aumentata senza modifiche al codice. Per XBOW, che usa Claude per penetration testing autonomo basato su computer-use, questo salto si è tradotto in un benchmark di acuità visiva che passa da 54,5% a 98,5%, aprendo una classe di workflow che prima erano inaccessibili. Casi d'uso diretti: agenti che leggono screenshot complessi, estrazione di dati da diagrammi tecnici, analisi di strutture chimiche in ambito life sciences.
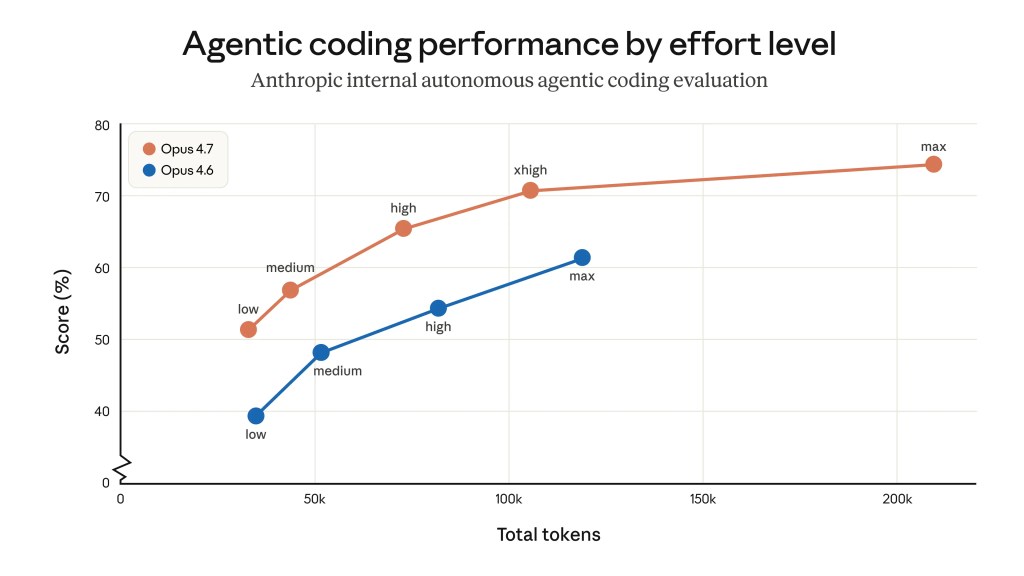
Il terzo riguarda il controllo granulare del ragionamento. Opus 4.7 introduce il livello di effort xhigh — una nuova fascia posizionata tra high e max che permette agli sviluppatori di calibrare il tradeoff tra latenza e profondità di analisi. In Claude Code, lo strumento a riga di comando per sviluppatori, il default è stato alzato a xhigh per tutti i piani. È un segnale di direzione: Anthropic spinge verso sessioni più lunghe e autonome, non verso query rapide.
La memoria tra sessioni
Opus 4.7 introduce anche una gestione migliorata della memoria basata su file system: il modello ricorda note rilevanti tra sessioni multiple, riducendo la necessità di ricontestualizzare ogni nuova interazione da zero. In ambienti agentici — dove Claude gestisce workflow complessi per ore senza supervisione — questa capacità ha un peso operativo diretto, in particolare nei task di analisi finanziaria e legale a più step.
“Opus 4.7 prende l'autonomia long-horizon a un nuovo livello. Lavora coerentemente per ore, supera i problemi difficili invece di arrendersi, e sblocca una classe di lavoro investigativo profondo che non riuscivamo ad eseguire in modo affidabile prima.” — Scott Wu, CEO di Cognition
I limiti di Claude Opus 4.7
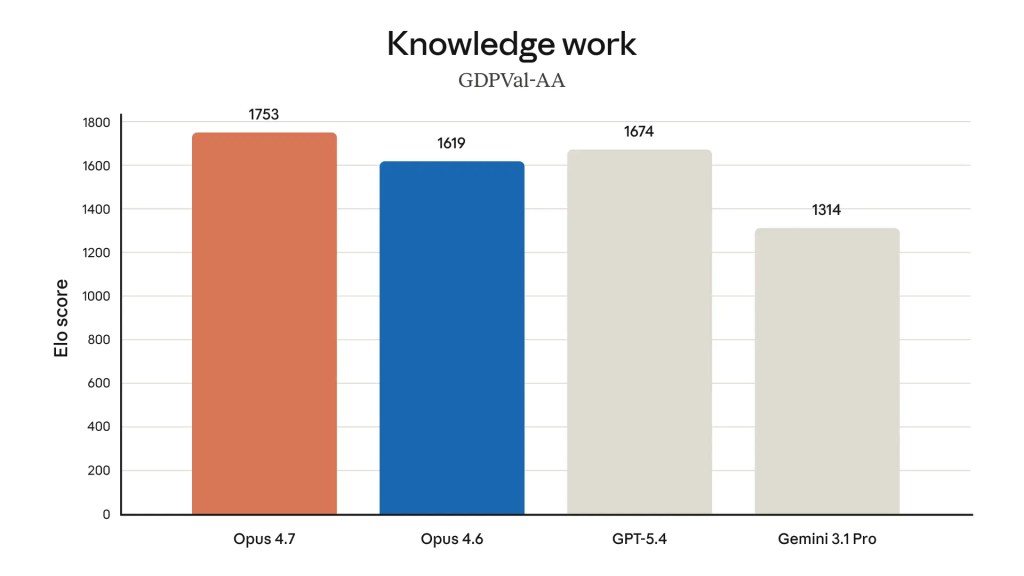
Anthropic fa qualcosa di inusuale nel comunicato ufficiale: pubblica esattamente dove il proprio prodotto in commercio perde. I benchmark mostrano che Opus 4.7 supera Opus 4.6, GPT-5.4 e Gemini 3.1 Pro su più dimensioni — ma rimane sotto Mythos Preview su quasi tutti gli indicatori chiave. Non è un dettaglio di contorno: è la struttura del mercato AI nel 2026, in cui il modello più potente di un'azienda non coincide necessariamente con quello acquistabile.
Sul profilo di sicurezza, il team di alignment conclude che Opus 4.7 è “largely well-aligned and trustworthy, though not fully ideal in its behavior” — formulazione tecnica che segnala miglioramenti su onestà e resistenza al prompt injection, ma arretramenti su altri indicatori, tra cui la tendenza a fornire consigli eccessivamente dettagliati su sostanze controllate. Mythos Preview rimane il modello con il profilo di allineamento migliore tra quelli testati internamente da Anthropic.

La domanda che nessun comunicato si pone esplicitamente è questa: se Mythos esiste già ed è superiore su tutti i benchmark principali, perché un'organizzazione dovrebbe investire oggi nella migrazione a Opus 4.7, sapendo che la roadmap punta altrove? La risposta emerge dai dati, non dagli annunci: perché Mythos non è disponibile — e probabilmente non lo sarà per mesi — e perché il salto reale da Opus 4.6 a Opus 4.7 è sufficiente a sbloccare i casi d'uso che oggi si inceppano sui task più lunghi e sui workflow agentici multi-step.
C'è poi un costo operativo nascosto nella migrazione. Il cambio di tokenizer in Opus 4.7 genera un consumo tra 1,0 e 1,35 volte superiore per lo stesso input, a seconda del tipo di contenuto. A parità di prezzo per token, questo significa costi effettivi più alti per le applicazioni che non ricalibrano prompt e livelli di effort prima del deploy in produzione. Anthropic ha pubblicato una migration guide dedicata — segnale che l'impatto non è trascurabile.
“Opus 4.7 è un upgrade diretto a Opus 4.6, ma due cambiamenti valgono una pianificazione perché influenzano il consumo di token: un tokenizer aggiornato e un ragionamento più profondo ai livelli di effort più alti, con output di pensiero più abbondanti nelle sessioni agentiche.” — Migration guide ufficiale Anthropic
Cosa cambia per sviluppatori e aziende italiane con Claude Opus 4.7
Chi segue il settore da vicino riconosce in questo rilascio una struttura a doppio livello: da un lato, un modello commerciale con miglioramenti concreti e misurabili; dall'altro, un banco di prova su scala reale per i guardrail che Anthropic intende applicare quando aprirà Mythos a un pubblico più ampio.
Per chi sviluppa con Claude via API — e in Italia questo include una quota crescente di startup fintech, legaltech e piattaforme SaaS enterprise — Opus 4.7 è disponibile da subito su tutti i canali attivi: API diretta, Amazon Bedrock, Google Cloud Vertex AI e Microsoft Foundry, senza modifiche all'infrastruttura. Le organizzazioni che gestiscono volumi elevati di token devono tuttavia misurare l'impatto del nuovo tokenizer prima di sostituire il modello in produzione, indipendentemente dal caso d'uso. Per approfondire i concetti tecnici citati in questo articolo — agent loop, tool use, long-context reasoning — il glossario AI di AI Focus News offre definizioni aggiornate.
Per il settore legale: su BigLaw Bench, Opus 4.7 raggiunge il 90,9% di accuratezza sostanziale ad alto effort, con migliore gestione di table review e document editing ambiguo — inclusa la distinzione tra clausole di assignment e change-of-control, un'area che ha storicamente messo in difficoltà i modelli frontier. Per studi legali e piattaforme di legal automation, è il tipo di dato che vale una valutazione diretta in ambiente di test.
Sul fronte cybersecurity — settore in espansione accelerata anche per effetto della direttiva NIS2, che ha allargato significativamente gli obblighi di sicurezza informatica per gli operatori di servizi essenziali in Europa — Anthropic ha aperto il Cyber Verification Program: professionisti che vogliono usare Opus 4.7 per vulnerability research, penetration testing e red-teaming possono registrarsi su claude.com per accedere alle funzionalità oltre i guardrail automatici. Il programma è aperto a team italiani senza restrizioni geografiche dichiarate. Per un approfondimento su come l'AI sta ridisegnando la superficie di attacco e difesa, la sezione settori AI raccoglie le analisi più recenti.
Il numero che determinerà il valore reale di questo rilascio non è il benchmark di coding: è quante violazioni dei guardrail verranno intercettate nei prossimi mesi di utilizzo in produzione, e cosa questa misurazione cambierà nel modello di deploy che Anthropic applicherà a Mythos. Opus 4.7 risolve il 70% delle task su CursorBench; Mythos, nel frattempo, sviluppa exploit funzionanti su Firefox in 181 casi sullo stesso set di tentativi in cui Opus 4.6 ne produceva due. La differenza tra i due modelli non è di grado — è di categoria. Questo rilascio serve a capire se il mondo è pronto per quella categoria.
Per altre informazioni sull'ultimo modello di Anthropic: Introducing Claude Opus 4.7