
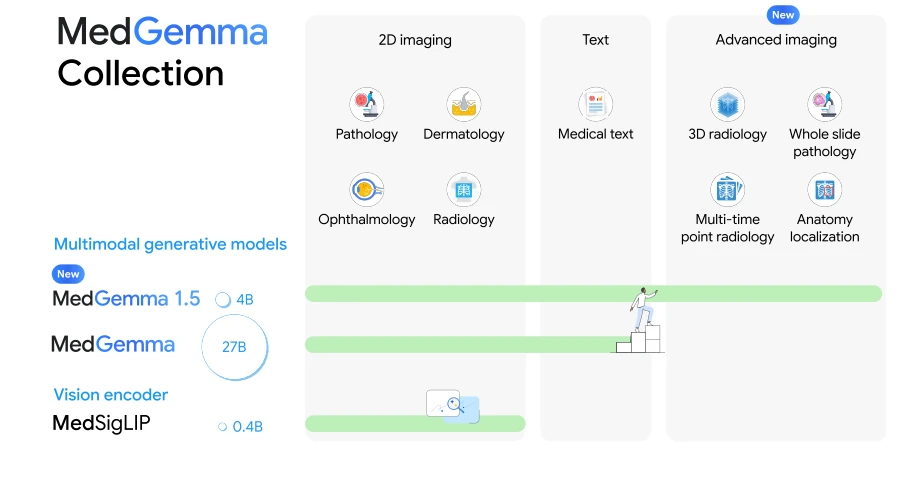
MedGemma 1.5 porta l'interpretazione di volumi CT, MRI e biopsie digitali in un modello open da 4 miliardi di parametri — e su istopatologia da whole-slide images segna un guadagno di 47 punti percentuali in macro F1 rispetto alla versione precedente. Il technical report è stato pubblicato da Google Research e Google DeepMind l'8 aprile 2026 su arXiv (2604.05081v1), insieme all'annuncio di MedASR, il modello speech-to-text medico che completa l'ecosistema.
Il rilascio non è un aggiornamento di routine. MedGemma 1.5 è il primo modello open-weight a unificare in un'unica architettura da 4B parametri la gestione di radiologia volumetrica 3D, istopatologia su preparati digitali, localizzazione anatomica e analisi longitudinale di radiografie — funzionalità che fino ad oggi richiedevano pipeline separate, dataset proprietari o accesso controllato a modelli chiusi con ordini di grandezza più parametri.
MedGemma 1.5: imaging volumetrico 3D, istologia e ragionamento clinico
MedGemma 1.5 4B è basato su Gemma 3 con encoder visivo MedSigLIP da 400 milioni di parametri. Rispetto alla versione 1, introduce quattro capacità multimodali native: interpretazione di volumi CT e MRI in tre dimensioni, analisi di whole-slide images (WSI) per istopatologia, localizzazione anatomica tramite bounding box su radiografie toraciche e ragionamento multi-timepoint su serie longitudinali.
Imaging 3D e istologia: i dati di benchmark
I miglioramenti rispetto a MedGemma 1 4B sono misurati su dataset clinici interni e pubblici. Sulla classificazione da volumi MRI 3D — che include lesioni cerebrali, patologie del ginocchio e del fegato — il modello raggiunge il 64,7% di accuracy contro il 51,3% precedente: +11 punti percentuali assoluti.
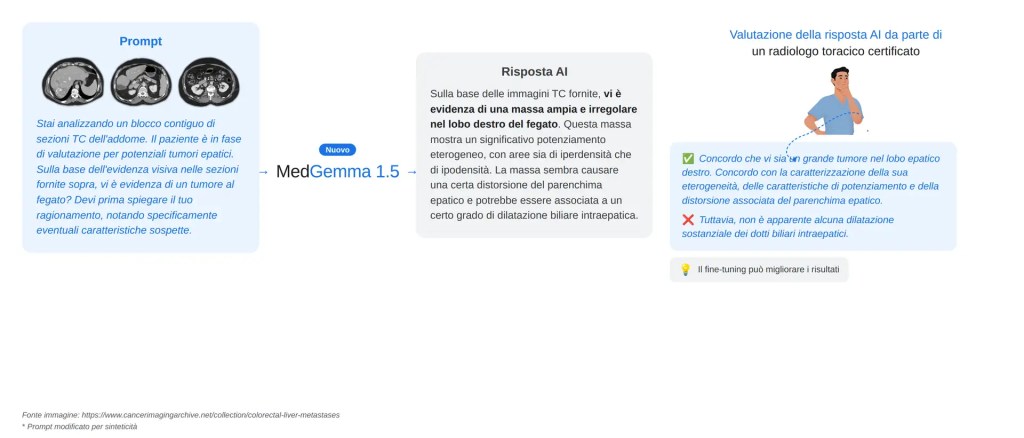
Sulla classificazione da volumi CT (testa, torace, addome/pelvi), sale dal 58,2% al 61,1%. Sul task più nuovo — generazione di report patologici da whole-slide images — il ROUGE-L passa da 2,2 a 49,4, un guadagno di 47 punti. La localizzazione anatomica su Rx torace (dataset Chest ImaGenome) migliora da una IoU media di 3,1 a 38,0: +35 punti. Sul versante testuale, MedQA cresce del 5% (da 64,4% a 69,1%) ed EHRQA — il benchmark per l'estrazione da cartelle cliniche elettroniche — balza dal 67,6% all'89,6%, un incremento del 22%.
Il technical report sintetizza l'intenzione strategica del rilascio:
“In quanto primo modello aperto a raggiungere queste diverse capacità di base in un'unica architettura, MedGemma 1.5 costituisce una base migliorata per la prossima generazione di sistemi di intelligenza artificiale medica.” — MedGemma 1.5 Technical Report, Google Research / Google DeepMind, aprile 2026
Per chi lavora nelle applicazioni AI in diagnostica e patologia digitale, questo significa disporre di un punto di partenza open — fine-tunabile su dati proprietari — senza dipendere da API chiuse o infrastrutture che escludono il deployment ospedaliero locale.
I trade-off che il paper non nasconde
L'espansione delle capacità ha un costo documentato. MedGemma 1.5 registra regressioni su alcuni benchmark consolidati: su SLAKE (visual question answering medico) il tokenized F1 scende da 72,3 a 59,8; su VQA-RAD cala da 49,9 a 48,1. Sul benchmark generale MMLU Pro, il modello degrada da 39,1% a 33,8% — conferma che la specializzazione medica intensiva ha eroso parte della capacità di ragionamento su domini non clinici.
Il model card è esplicito sul perimetro d'uso:
“Il modello non è destinato a essere distribuito senza il necessario affinamento clinico.” — MedGemma 1.5 Model Card, Health AI Developer Foundations, 2026
Il modello è anche più sensibile al prompt rispetto a Gemma 3 base, il che può produrre variazioni nei risultati in funzione della formulazione delle query — un aspetto che richiede validazione sistematica prima di qualsiasi deploy clinico. Sul piano architetturale, i volumi CT vengono ridotti a sequenze di massimo 85 slice assiali 2D per restare entro 32.000 token, introducendo un compromesso tra completezza dell'analisi e vincoli di memoria. Google segnala anche il rischio di data contamination nei benchmark pubblici — variabile che può gonfiare artificialmente le performance misurate.
4B parametri contro architetture chiuse: la logica del deployment
Il confronto più rilevante per sviluppatori e decision-maker sanitari non è tra MedGemma 1.5 e Gemini Pro — è tra MedGemma 1.5 e Med-PaLM 2.
Med-PaLM 2, pubblicato da Google nel 2023 e basato sull'architettura chiusa PaLM 2, aveva raggiunto l'86,5% su MedQA USMLE-style — allora un nuovo stato dell'arte assoluto — superando i medici su otto dei nove assi clinici valutati in pairwise ranking su 1.066 domande. Ma Med-PaLM 2 è accessibile solo via API controllata, non disponibile per fine-tuning e non eseguibile on-premise. MedGemma 1.5 opera con 4 miliardi di parametri, i pesi sono rilasciati apertamente sotto la Health AI Developer Foundations License — che consente uso di ricerca e commerciale con accettazione dei termini — ed è eseguibile localmente su hardware ospedaliero standard, su Google Cloud Vertex AI o su dispositivi edge con vincoli di risorse.
Ciò non significa performance equivalenti: MedGemma 1.5 rimane circa 17 punti sotto Med-PaLM 2 su MedQA. Ma nella logica del deployment reale — un dipartimento di radiologia che vuole integrare AI nella refertazione senza dipendenze cloud esterne — la differenza tra un modello eseguibile localmente e uno inaccessibile è operativamente più rilevante dello scarto sui benchmark standardizzati. È la stessa tensione che attraversa l'intero settore dell'AI in sanità: tra massima accuratezza in laboratorio e massima usabilità sul campo.
MedGemma nel SSN: radiologia, patologia digitale e l'ecosistema end-to-end
MedGemma 1.5 è il nodo centrale di un ecosistema aperto più ampio. MedASR — modello speech-to-text da 105 milioni di parametri addestrato su circa 5.000 ore di dettati medici de-identificati in radiologia, medicina interna e medicina di famiglia — si integra direttamente con MedGemma per costruire pipeline end-to-end: il clinico detta il referto, MedASR trascrive con il 58% di errori in meno rispetto a Whisper large-v3 sulle dettature radiologiche (5,2% vs 12,5% word error rate), MedGemma 1.5 riceve testo e immagini per ragionamento clinico integrato. Tutto open, tutto fine-tunabile, tutto accessibile via Hugging Face o Vertex AI, con supporto DICOM nativo per workflow radiologici.
Per il SSN italiano, il dato strutturalmente rilevante è la scalabilità su hardware locale. La carenza di radiologi e anatomopatologi è documentata — con tempi medi di refertazione su TC multistrato e RM encefalo che in alcune ASL superano le tre settimane — e il supporto decisionale AI su imaging 3D e preparati istologici digitali rappresenta un'ipotesi concreta di riduzione del collo di bottiglia diagnostico, non un'applicazione futuribile. Un modello che interpreta nativamente volumi CT e whole-slide images senza dipendere da API esterne è compatibile con i vincoli di sovranità del dato imposti dalla normativa italiana sul trattamento di dati sanitari.
Sul piano della governance, il rilascio prevede valutazioni di sicurezza interne condotte separatamente dal team di sviluppo e supervisionate da un Responsibility & Safety Council. Tutti i test — su child safety, content safety e representational harms — hanno restituito livelli minimi di violazioni. I termini della Health AI Developer Foundations License impongono vincoli espliciti sull'uso clinico autonomo e richiedono validazione indipendente prima del deploy su pazienti reali: una distinzione tra strumento per sviluppatori e dispositivo medico certificato che il paper ribadisce in più punti.
Il MedGemma Impact Challenge lanciato su Kaggle — 100.000 dollari in premi per applicazioni costruite sulla MedGemma Collection — misura l'interesse concreto dell'ecosistema: milioni di download e centinaia di varianti pubblicate su Hugging Face nel solo anno successivo al rilascio iniziale. Nella storia dell'AI medica open-weight, non esistono precedenti con questa scala di adozione.
Repository GitHub: https://github.com/google-health/medgemma
Fonti primarie: Sellergren, A., Gao, C., et al. MedGemma 1.5 Technical Report. arXiv:2604.05081v1, Google Research / Google DeepMind, 6 aprile 2026. — Singhal, K. et al. Towards Expert-Level Medical Question Answering with Large Language Models. arXiv:2305.09617v1, Google Research, maggio 2023. — Google Health AI. MedGemma 1.5 Model Card, Health AI Developer Foundations, gennaio 2026. — Google Research Blog. Next generation medical image interpretation with MedGemma 1.5 and medical speech to text with MedASR, 8 aprile 2026.