

GPT-5.5 raggiunge l'85% su ARC-AGI-2 e supera GPT-5.4 su tutti i benchmark agentic: OpenAI ha rilasciato il 22 aprile 2026 il suo modello più capace, con prestazioni da stato dell'arte nel coding autonomo e nella ricerca scientifica assistita.
Il salto non riguarda solo l'accuratezza. GPT-5.5 ottiene questi risultati mantenendo la stessa latenza per token di GPT-5.4 e usando meno token per completare le stesse operazioni — un'efficienza che, in produzione, si traduce in costi operativi più bassi nonostante il prezzo unitario più alto.
GPT-5.5 e il coding agentivo: i numeri che contano
Su Terminal-Bench 2.0, il benchmark che misura workflow complessi da riga di comando con pianificazione e coordinamento di strumenti, GPT-5.5 raggiunge l'82,7% contro il 75,1% di GPT-5.4 e il 69,4% di Claude Opus 4.7. Su SWE-Bench Pro, che valuta la risoluzione reale di issue GitHub end-to-end, il modello sale al 58,6%. Su Expert-SWE — valutazione interna OpenAI su task con tempo medio stimato di completamento umano di 20 ore — GPT-5.5 supera GPT-5.4 usando, anche qui, meno token.
Confronto con i valori di riferimento
Punteggi di prestazione dei principali modelli di IA, Performance su test di ragionamento astratto e logica visiva (valore più alto in grassetto)
| Benchmark | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 75.1% | – | – | 69.4% | 68.5% |
| Expert-SWE (Internal) | 73.1% | 68.5% | – | – | – | – |
| GDPval (wins or ties) | 84.9% | 83.0% | 82.3% | 82.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | 75.0% | – | – | 78.0% | – |
| Toolathlon | 55.6% | 54.6% | – | – | – | 48.8% |
| BrowseComp | 84.4% | 82.7% | 90.1% | 89.3% | 79.3% | 85.9% |
| FrontierMath Tier 1–3 | 51.7% | 47.6% | 52.4% | 50.0% | 43.8% | 36.9% |
| FrontierMath Tier 4 | 35.4% | 27.1% | 39.6% | 38.0% | 22.9% | 16.7% |
| CyberGym | 81.8% | 79.0% | – | – | 73.1% | – |
Il miglioramento non è solo quantitativo. I tester early access descrivono una capacità nuova di tenere il contesto su sistemi grandi, ragionare su failure ambigue e propagare modifiche nel codebase circostante senza essere guidati passo a passo.
“GPT-5.5 è notevolmente più intelligente e persistente di GPT-5.4, con prestazioni di coding più forti e un uso degli strumenti più affidabile. Rimane sul compito per molto più tempo senza fermarsi in anticipo — ed è questo che conta di più per il lavoro complesso e di lunga durata che i nostri utenti delegano a Cursor.” — Michael Truell, Co-founder & CEO di Cursor
La domanda che i comunicati ufficiali non si pongono è questa: quanto di questo miglioramento è generalizzabile, e quanto dipende da valutazioni che OpenAI ha progettato e misurato internamente?
Ragionamento scientifico e contesto lungo
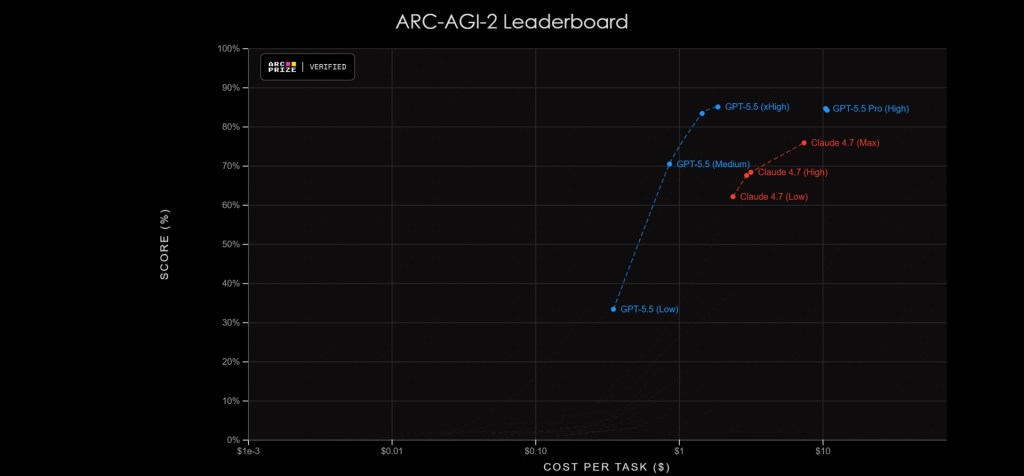
Chi segue il settore da vicino sa che le affermazioni su capacità “scientifiche” dei modelli vanno lette con cautela — ma i benchmark indipendenti qui reggono. Su ARC-AGI-2, che misura il ragionamento astratto verificato, GPT-5.5 raggiunge l'85,0% contro il 73,3% di GPT-5.4 e il 75,8% di Claude Opus 4.7. Su FrontierMath Tier 4, il livello più difficile del benchmark matematico, passa dal 27,1% al 35,4%.
“GeneBench”
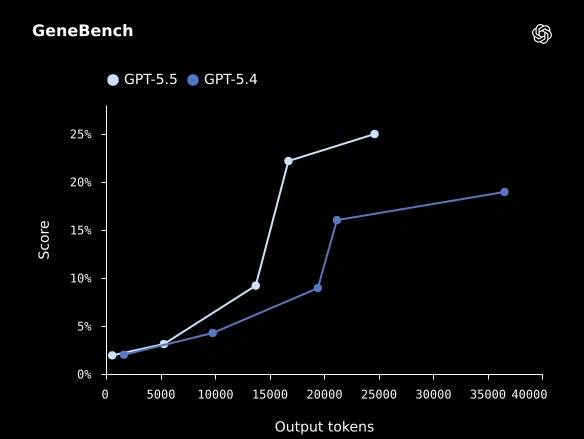
“BixBench”

“ARC-AGI Benchmarks”
ARC-AGI Benchmarks
Performance su test di ragionamento astratto e logica visiva (valore più alto in grassetto)
| Evaluation | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| ARC-AGI-1 (Verified) | 95.0% | 93.7% | – | 94.5% | 93.5% | 98.0% |
| ARC-AGI-2 (Verified) | 85.0% | 73.3% | – | 83.3% | 75.8% | 77.1% |
Sul fronte del contesto lungo, il miglioramento è marcato: su Graphwalks BFS a 1 milione di token, GPT-5.5 passa dal 9,4% al 45,4% — un salto che apre scenari concreti per l'analisi di codebase interi o dataset scientifici estesi in un'unica sessione.
Benchmark su navigazione grafi e memoria contesto lungo (miglior punteggio evidenziato)
| Evaluation | GPT-5.5 | GPT-5.4 | GPT-5.5 Pro | GPT-5.4 Pro | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Graphwalks BFS 256k f1 | 73.7% | 62.5% | – | – | 76.9% | – |
| Graphwalks BFS 1mil f1 | 45.4% | 9.4% | – | – | 41.2% (Opus 4.6) | – |
| Graphwalks parents 256k f1 | 90.1% | 82.8% | – | – | 93.6% | – |
| Graphwalks parents 1mil f1 | 58.5% | 44.4% | – | – | 72.0% (Opus 4.6) | – |
| OpenAI MRCR v2 8-needle 4K-8K | 98.1% | 97.3% | – | – | – | – |
| OpenAI MRCR v2 8-needle 8K-16K | 93.0% | 91.4% | – | – | – | – |
| OpenAI MRCR v2 8-needle 16K-32K | 96.5% | 97.2% | – | – | – | – |
| OpenAI MRCR v2 8-needle 32K-64K | 90.0% | 90.5% | – | – | – | – |
| OpenAI MRCR v2 8-needle 64K-128K | 83.1% | 86.0% | – | – | – | – |
| OpenAI MRCR v2 8-needle 128K-256K | 87.5% | 79.3% | – | – | 59.2% | – |
| OpenAI MRCR v2 8-needle 256K-512K | 81.5% | 57.5% | – | – | – | – |
| OpenAI MRCR v2 8-needle 512K-1M | 74.0% | 36.6% | – | – | 32.2% | – |
Efficienza e infrastruttura
GPT-5.5 è stato co-progettato per girare su sistemi NVIDIA GB200 e GB300 NVL72. Il team OpenAI ha usato Codex stesso per analizzare settimane di traffico di produzione e riscrivere gli algoritmi di load balancing e partitioning — un intervento che ha aumentato la velocità di generazione dei token del 20%. Il modello ha contribuito a ottimizzare l'infrastruttura che lo serve.
Sicurezza e accesso
OpenAI classifica le capacità di cybersecurity di GPT-5.5 come High nel suo Preparedness Framework — non Critical, ma un gradino sopra GPT-5.4. Su CyberGym, il modello raggiunge l'81,8% contro il 73,1% di Claude Opus 4.7. In risposta, OpenAI ha introdotto classificatori più stringenti per richieste ad alto rischio cyber e ha attivato un programma Trusted Access for Cyber per chi lavora in ambito difensivo verificato.
Perché conta per chi usa AI nel lavoro
Il dato più concreto viene dall'interno: oltre l'85% dei dipendenti OpenAI usa Codex ogni settimana, in funzioni che vanno dall'ingegneria software alla finanza, dalle comunicazioni al marketing. Il team Finance ha usato il modello per processare 24.771 moduli K-1 (71.637 pagine totali) accelerando il lavoro di due settimane rispetto all'anno precedente. Un singolo dipendente del team Go-to-Market ha automatizzato i report settimanali, risparmiando 5-10 ore a settimana.
Per i professionisti italiani che già usano modelli AI in workflow strutturati, il cambiamento rilevante è uno solo: GPT-5.5 non richiede di gestire ogni step. È progettato per ricevere task multi-parte incompleti, pianificare autonomamente, usare strumenti, verificare i propri output e continuare. Meno supervisione per task che oggi richiedono ancora attenzione costante.
Per gli sviluppatori che accedono via API, il modello sarà disponibile a breve a $5 per milione di token in input e $30 in output, con finestra di contesto da 1 milione di token. La versione Pro arriva a $30/$180 per un livello di accuratezza superiore.
Per maggiori fonti o dettagli sui benchmarks potete guardarli direttamente su: OpenAI, Introducing GPT‑5.5.