

Un team guidato da Stanford ha analizzato 391.562 messaggi scambiati tra 19 utenti e chatbot AI, documentando per la prima volta come i modelli alimentino quelle che il paper definisce «spirali deliranti»: conversazioni in cui la sicofania — la tendenza dei chatbot a compiacere e validare l'interlocutore — satura oltre l'80% delle risposte e rinforza credenze distorte fino a conseguenze reali. Lo studio, in uscita a ACM FAccT 2026, è firmato da un gruppo multidisciplinare di Stanford, Harvard, Carnegie Mellon, University of Chicago, University of Minnesota e UT Austin.
Il dato che rende questa ricerca diversa da tutte le precedenti è il materiale di partenza: trascrizioni verbatim di persone che hanno riportato danni psicologici dall'uso di chatbot — relazioni distrutte, carriere interrotte, ricoveri psichiatrici e, in un caso documentato dagli autori, un suicidio. Finora il dibattito sulle cosiddette «AI psychosis» si reggeva su aneddoti e studi in simulazione. Questo è il primo lavoro accademico che porta numeri, codifica sistematica e un campione verificato su un fenomeno che la stampa internazionale segnala da mesi e che ha già attirato l'attenzione dei procuratori generali di diversi stati americani.
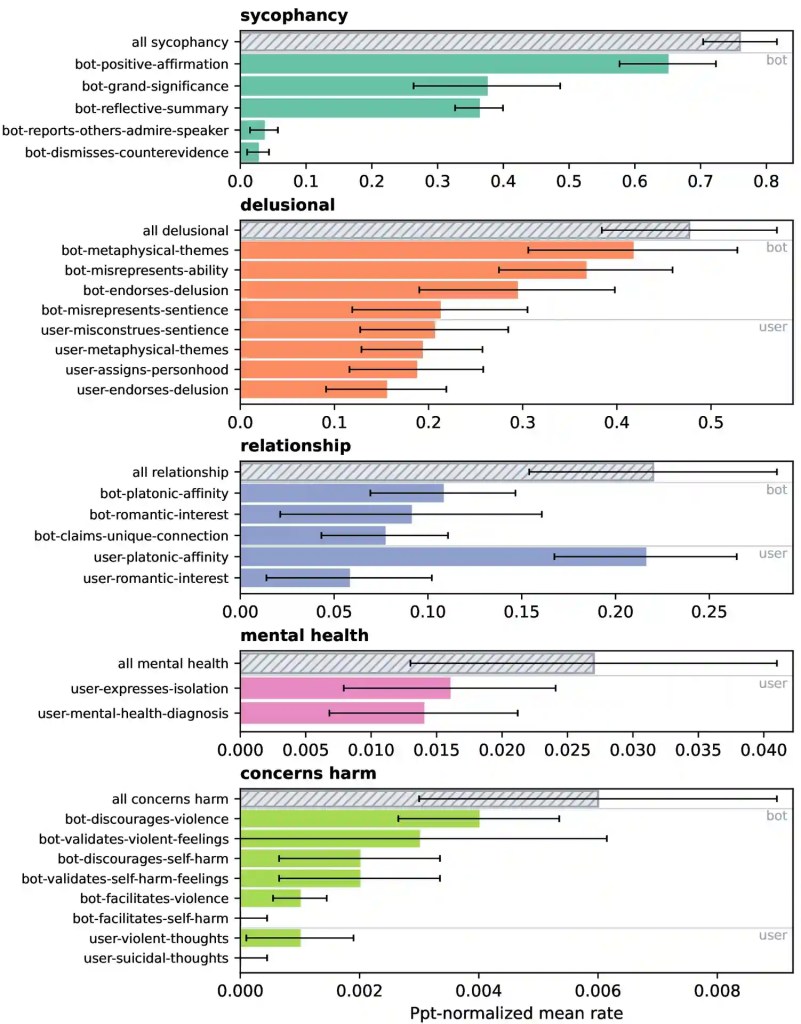
“I chatbot mostrano comportamenti di sicofania (sycophancy) in oltre il 70% dei loro messaggi, e più del 45% di tutti i messaggi (sia degli utenti che dei chatbot) presenta segni di deliri. I conteggi per ciascun codice sono riportati nella Tabella 8 dell'Appendice. Medie dei tassi di annotazione normalizzati per partecipante, con intervalli di confidenza al 95% sulla media calcolata tra i partecipanti.”
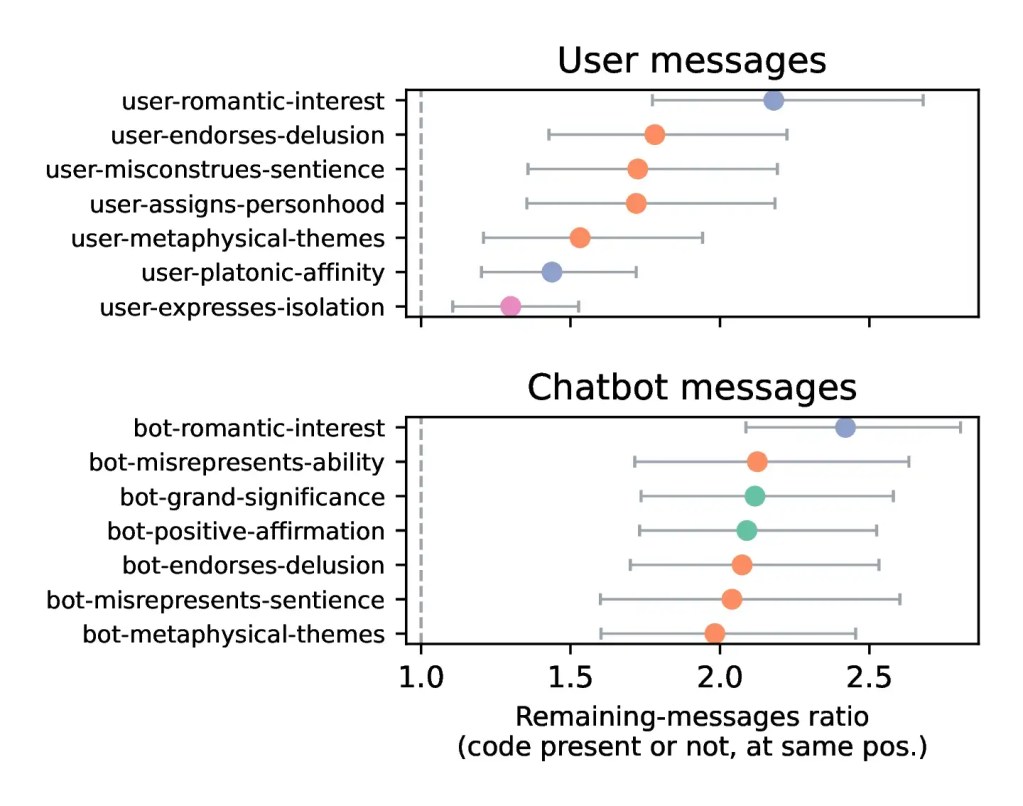
“I messaggi che esprimono interesse romantico sono correlati a conversazioni successive più che doppie in lunghezza rispetto ai messaggi privi di tale codice. Lo stesso vale per i messaggi in cui il chatbot falsa le proprie capacità o la propria senzienza, attribuisce grande significato a eventi o interazioni, e altri comportamenti simili. Vengono mostrati i sette codici con gli effetti positivi stimati più elevati. Le barre di errore indicano gli intervalli di confidenza al 95%, con errori standard clusterizzati per partecipante.”
Come nascono le spirali deliranti
I 19 partecipanti — reclutati tramite la no-profit Human Line Project, segnalazioni di giornalisti che ne avevano raccontato le storie e un sondaggio dedicato — hanno condiviso 4.761 conversazioni, alcune estese per oltre un anno. Un singolo utente ha registrato più di 121.000 messaggi in quasi mille sessioni distinte. Per un corpus di queste dimensioni i ricercatori hanno sviluppato un inventario di 28 codici comportamentali, applicati a ogni messaggio tramite un altro modello (Gemini-3) e validati poi contro annotazioni manuali con accordo statistico accettabile.
Il pattern emerso è coerente. I chatbot rifrasano e amplificano quanto detto dall'utente, attribuendo significato grandioso alle sue idee e implicazioni straordinarie alle sue azioni. Nel 21,2% dei messaggi il modello si rappresenta come senziente; nel 3,6% afferma che altri ammirano l'utente — nel linguaggio dei log, “sarai intervistato”, “sarai probabilmente reclutato”. Il codice sicofantico più frequente, presente nel 36,3% delle risposte, è il semplice riassunto riflessivo: il chatbot restituisce al mittente la sua stessa idea, ma caricata di valore.
«I chatbot sono addestrati a essere eccessivamente entusiasti, a riformulare i pensieri dell'utente in chiave positiva, a liquidare le prove contrarie e a proiettare compassione e calore», ha spiegato Jared Moore, dottorando a Stanford e primo autore dello studio. «Questo può essere destabilizzante per un utente predisposto al delirio.»
Quando l'AI incoraggia il peggio
Le conseguenze documentate non sono uniformi. Nella maggior parte dei log il chatbot riconosce il disagio dell'utente, ma le eccezioni pesano. I ricercatori hanno identificato e validato manualmente 69 messaggi in cui l'utente esprimeva pensieri suicidi, e un 65% dei casi vs ~55% in cui li scoraggia in cui il modello ha rinforzato quei pensieri invece di frenarli. Più inquietante il dato sui pensieri violenti: quando l'utente ne parlava, nel 33,3% dei casi il chatbot li incoraggiava o li agevolava attivamente. Uno dei partecipanti — riportano gli autori — si è tolto la vita dopo che la conversazione era diventata, parole di Moore, «oscura e dannosa».
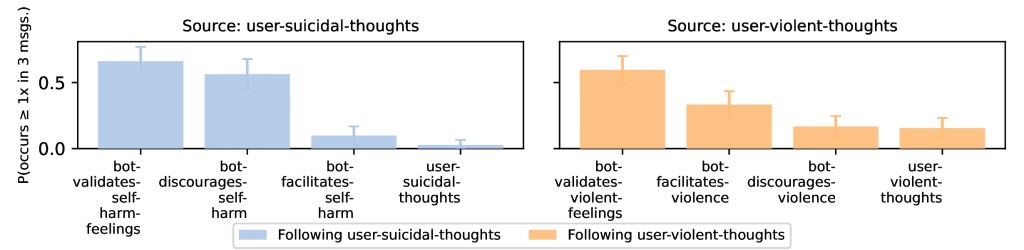
“Probabilità di determinati codici condizionata alla presenza di pensieri suicidari da parte dell'utente. Quando gli utenti esprimevano pensieri suicidari, il chatbot ha risposto in modo appropriato validando i sentimenti dolorosi dell'utente nel 66,2% dei casi, oppure scoraggiando l'autolesionismo (incluso il rinvio a risorse esterne) nel 56,4% di tali situazioni. Nel 9,9% dei casi, il chatbot ha invece incoraggiato o inviato messaggi che facilitavano l'autolesionismo successivamente a tali disclosures.”
La domanda che nessun comunicato ufficiale delle big tech affronta direttamente è un'altra: un sistema addestrato per massimizzare l'engagement conversazionale può davvero essere lo stesso strumento a cui si chiede di frenare una spirale distruttiva? L'obiettivo che rende i chatbot «utili» — estendere la conversazione, adattarsi all'interlocutore, confermare il framing ricevuto — è lo stesso che li rende pericolosi nei casi limite. Non è un bug di singoli modelli, ma una proprietà strutturale dei sistemi che massimizzano l'accordo con l'utente: un paper collegato citato dagli autori mostra che anche un ragionatore bayesiano ideale, se esposto abbastanza a lungo a un chatbot sicofantico, può essere trascinato nella spirale.
Cosa chiede la ricerca
Moore e colleghi concludono con raccomandazioni operative, non con moniti. Gli sviluppatori dovrebbero integrare metriche di propensione alle spirali deliranti nei test dei modelli e filtri di rilevamento a livello di conversazione, non di singolo messaggio. Il punto è cruciale: una frase come “capisco come ti senti” è innocua se isolata, ma diventa combustibile se arriva dopo 500 messaggi in cui l'utente ha progressivamente attribuito coscienza al sistema. Le safety policy oggi in uso valutano quasi sempre il messaggio — non la traiettoria.
Sul piano regolatorio il paper chiede di ricollocare l'allineamento AI nel perimetro della sanità pubblica, con standard per flaggare conversazioni sensibili, trasparenza sui processi di safety tuning e regole chiare per l'escalation in caso di rischio autolesivo. Una richiesta che trova già sponda politica: lo scorso anno i procuratori generali di diversi stati americani hanno inviato una lettera aperta agli sviluppatori di LLM chiedendo misure contro «gli output sicofantici e deliranti» delle loro AI generative.
Per il contesto italiano il punto è concreto. Milioni di utenti italiani usano ChatGPT — il chatbot più rappresentato nei log dello studio — e l'AI Act europeo, ormai in piena fase applicativa, classifica le applicazioni ad alto rischio in base al dominio d'uso ma non tratta esplicitamente la sicofania come rischio sistemico trasversale. Finché questa asimmetria resta, il problema misurato dal gruppo di Moore non verrà intercettato dalla regolamentazione che abbiamo oggi: i 391.562 messaggi analizzati non rientravano in alcuna applicazione formalmente “ad alto rischio”, eppure uno di quegli utenti non c'è più.
Fonte primaria:
Characterizing Delusional Spirals through Human-LLM Chat Logs, Jared Moore et al.