
Gemini Robotics-ER 1.6, il nuovo modello di embodied reasoning per robotica di Google DeepMind, migliora del 10% il rilevamento di rischi fisici in scenari video rispetto a Gemini 3.0 Flash e introduce per la prima volta la capacità di leggere strumenti industriali analogici — manometri, indicatori di livello, sight glass chimici. Disponibile tramite Gemini API e Google AI Studio, ER 1.6 è l’ultimo passo di una traiettoria precisa: spostare l’AI robotica dal seguire istruzioni al ragionare sul mondo fisico, colmando il divario tra intelligenza digitale e azione meccanica.
Il panorama della robotica AI si è strutturato in due architetture distinte. Da un lato, i vision-language-action model (VLA) come RT-2 che mappano direttamente immagine e linguaggio in comandi motori. Dall’altro, modelli di ragionamento di alto livello che non controllano direttamente i motori ma pianificano, interpretano e delegano. ER 1.6 appartiene alla seconda categoria: opera come cervello deliberativo, capace di chiamare nativamente strumenti esterni — Google Search, VLA di terze parti, funzioni definite dall’utente — per tradurre il ragionamento in azione fisica. L’embodied reasoning non è quindi un nuovo tipo di modello, ma un paradigma che separa il “pensare” dal “muovere”, con implicazioni architetturali profonde per chi progetta sistemi robotici.

Figura 1: Risultati dei benchmark a confronto tra Gemini Robotics-ER 1.6 e i modelli Gemini Robotics-ER 1.5 e Gemini 3.0 Flash. Le valutazioni relative alla lettura degli strumenti sono state eseguite con la funzionalità “agentic vision” abilitata (ad eccezione di Gemini Robotics-ER 1.5, che non la supporta). Tutte le altre valutazioni sono state condotte con “agentic vision” disabilitata. Le valutazioni di rilevamento del successo a vista singola e multivista contengono esempi differenti e pertanto non sono direttamente confrontabili.
L’embodied reasoning di ER 1.6: come funziona
Il modello costruisce il suo ragionamento spaziale su tre pilastri: il pointing, la rilevazione del completamento dei task e la lettura di strumenti. Il pointing — la capacità di generare coordinate specifiche in un’immagine — non è un’annotazione banale. ER 1.6 lo usa come passaggio intermedio per ragionare su task complessi: contare oggetti in una scena, identificare relazioni spaziali come “da X a Y”, o definire i punti di presa ottimali per un gripper. Nei test pubblicati, il modello identifica correttamente 6 pinze, 2 martelli e 1 paio di forbici in un’unica immagine dove la versione precedente sbagliava il conteggio dei martelli e hallucinava un carriola assente dal frame.
Più significativo: ER 1.6 sa quando non puntare — non indica oggetti richiesti ma non presenti nell’immagine, una forma di ragionamento negativo che le generazioni precedenti non possedevano. Il pointing viene inoltre usato per il rispetto di vincoli complessi — ad esempio “indica ogni oggetto abbastanza piccolo da entrare nella tazza blu” — dove il modello deve combinare stima dimensionale, classificazione e logica relazionale in un singolo passo.

Figura 2: Gemini Robotics-ER 1.6 identifica correttamente il numero di martelli (2), forbici (1), pennelli (1), pinze (6) e un insieme di attrezzi da giardino, che può essere interpretato come un unico gruppo o come più punti distinti. Inoltre, non indica oggetti richiesti ma assenti nell’immagine, come una carriola e un trapano Ryobi.
Al confronto, Gemini Robotics-ER 1.5 non riesce a identificare il numero corretto di martelli o pennelli, omette completamente le forbici, “allucina” la presenza di una carriola (segnalandola pur non essendo presente) e mostra scarsa precisione nel puntamento delle pinze.
Gemini 3.0 Flash si avvicina alle prestazioni di Gemini Robotics-ER 1.6, ma gestisce le pinze in modo meno efficace.
Agentic vision e lettura di strumenti industriali
La novità tecnicamente più rilevante è la lettura di strumenti, capacità sviluppata in collaborazione con Boston Dynamics per rispondere a un bisogno reale delle ispezioni di impianto. Un robot Spot in uno stabilimento chimico incontra manometri circolari con aghi multipli — ognuno riferito a una diversa cifra decimale —, indicatori di livello verticale con distorsione prospettica, sight glass con liquidi parzialmente visibili.
ER 1.6 affronta questo problema combinando agentic vision ed esecuzione di codice in un loop: prima zooma sui dettagli dell’immagine per leggere tick mark e testi, poi usa il pointing per stimare proporzioni e intervalli tramite calcolo numerico, infine applica la conoscenza del mondo per interpretare il valore — ad esempio combinando la lettura di due aghi in un unico numero decimale. Non è semplice classificazione visiva: è ragionamento geometrico e fisico applicato a un’immagine.
La rilevazione del completamento task è avanzata nella logica multi-vista. In un setup robotico tipico con telecamera a soffitto e telecamera da polso, il sistema deve integrare flussi visivi diversi e decidere se l’azione è riuscita anche con occlusioni parziali o illuminazione scarsa. ER 1.6 supera ER 1.5 su tutti i benchmark di single-view e multi-view success detection — la capacità di sincronizzare punti di vista diversi nel tempo è critica per task sequenziali come “prendi la penna blu e inseriscila nel portapenne nero”, dove l’azione viene decomposta in sotto-goal e verificata visivamente dopo ogni passaggio.
“From navigating a complex facility to interpreting the needle on a pressure gauge, a robot’s ‘embodied reasoning’ is what allows it to bridge the gap between digital intelligence and physical action.” — Laura Graesser e Peng Xu, Google DeepMind
I limiti che l’annuncio non nasconde
Google DeepMind è insolitamente esplicito sulle fragilità del modello. Al termine del post ufficiale, l’invito è letterale: se le capacità sono insufficienti per la vostra applicazione specializzata, inviate 10-50 immagini etichettate che illustrino casi di fallimento specifici. È un’ammissione programmatica che il modello non copre la lunga coda di situazioni reali e che i benchmark di laboratorio, per quanto migliorati, restano un’approssimazione del caos di un impianto industriale in opera.
Il documento non riporta latenze di inferenza, requisiti computazionali né tassi di fallimento in deploy operativo — dati determinali per chi debba valutare l’integrazione di ER 1.6 in un sistema robotico in produzione. La lettura di strumenti è stata testata su un set ristretto di tipologie di manometri e sight glass; la varietà del parco strumenti negli impianti industriali italiani, dove convivono dispositivi decennali con standard di fabbricazione diversi, rappresenta una sfida non quantificata dall’annuncio.
Sul fronte sicurezza, il quadro è misto: ER 1.6 migliora rispetto a ER 1.5 nel rispetto dei vincoli di sicurezza fisica — “non manipolare liquidi”, “non sollevare oggetti oltre 20 kg” — e supera Gemini 3.0 Flash nel rilevamento rischi video (+10%) e testo (+6%). Tuttavia, sulle valutazioni con bounding box, Gemini 3.0 Flash resta superiore, suggerendo che il trade-off tra precisione del pointing e accuratezza dei bounding non è stato ancora risolto.
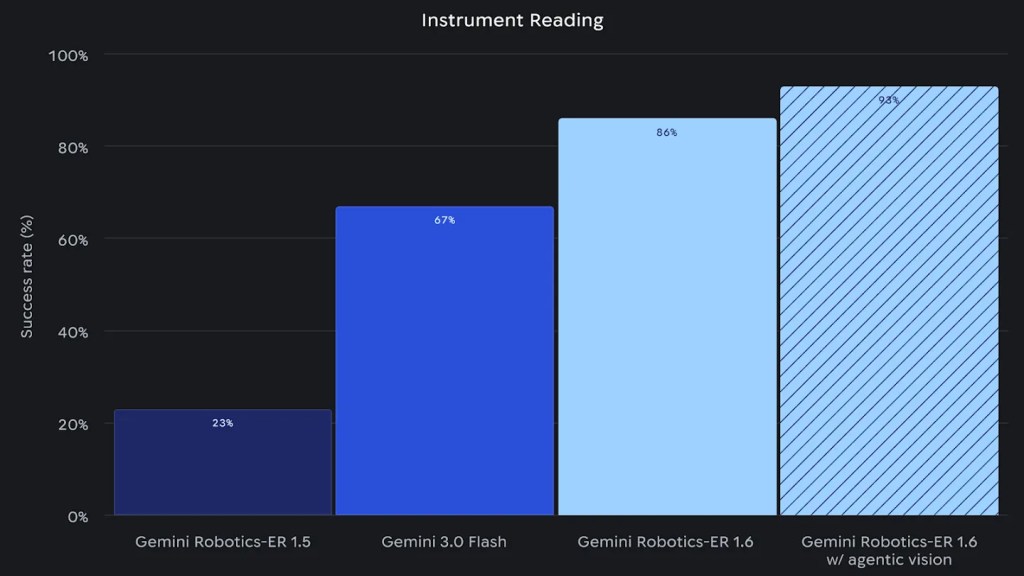
Figura 3: Gemini Robotics-ER 1.6 mostra un miglioramento sostanziale rispetto a Gemini Robotics-ER 1.5 nel seguire le istruzioni di sicurezza, un test che valuta la capacità di rispettare i vincoli di sicurezza fisica. Rispetto a Gemini 3.0 Flash, invece, migliora nelle prestazioni di puntamento, mentre entrambi i modelli raggiungono un’accuratezza molto elevata per il testo. Gemini 3.0 Flash, d’altro canto, ottiene risultati migliori nella generazione di bounding box.
Embodied reasoning e industria italiana: tre implicazioni
La partnership con Boston Dynamics è il segnale strategico più rilevante dell’annuncio. Non si tratta di una demo accademica: Spot è un robot commerciale già operativo in impianti industriali, e la lettura di strumenti risolve un collo di bottiglia concreto nelle ispezioni di stabilimenti chimici, petrolchimici e alimentari.
“Capabilities like instrument reading and more reliable task reasoning will enable Spot to see, understand, and react to real-world challenges completely autonomously.” — Marco da Silva, Vice President e General Manager di Spot, Boston Dynamics
In Italia, dove il patrimonio manifatturiero è il secondo in Europa e dove le ispezioni visive sugli impianti sono ancora largamente manuali — un processo che dipende dalla disponibilità di tecnici qualificati e che nei turni notturni o in aree a rischio diventa un collo di bottiglia operativo e di sicurezza —, un modello capace di interpretare strumenti analogici senza addestramento specifico per impianto abbassa il costo di integrazione in modo misurabile.
Le aziende italiane che valutano soluzioni di robotica autonoma per ispezioni devono considerare tre implicazioni concrete. Primo: ER 1.6 è accessibile via API, quindi non serve un robot Boston Dynamics per sfruttarne le capacità di ragionamento visivo — basta un sistema con telecamera e connettività. Secondo: il modello è progettato come strato deliberativo sopra VLA esistenti, quindi si integra con architetture robotiche già in campo senza riscriverle. Terzo: la richiesta aperta di immagini di fallimento è un’opportunità competitiva — le aziende che forniscono dati specifici del proprio dominio ottengono peso nella roadmap di sviluppo.
Il dato che resta: ER 1.6 rileva il 10% in più di rischi di infortunio in video e il 6% in più in testo rispetto a Gemini 3.0 Flash. Per un sistema che opera in stabilimenti con personale umano presente, questo margine non è un miglioramento incrementale — è la differenza tra un rischio identificato e un incidente sul lavoro.
Fonte: